
CAMOUFLAGE IS ALL YOU NEED: EVALUATING AND ENHANCING
LANGUAGE MODEL ROBUSTNESS AGAINST CAMOUFLAGE
ADVERSARIAL ATTACKS
A PREPRINT
Álvaro Huertas-García
Department of Computer Systems Engineering
Universidad Politécnica de Madrid
Madrid, Spain
Alejandro Martín
Department of Computer Systems Engineering
Universidad Politécnica de Madrid
Madrid, Spain
Javier Huertas-Tato
Department of Computer Systems Engineering
Universidad Politécnica de Madrid
Madrid, Spain
David Camacho
Department of Computer Systems Engineering
Universidad Politécnica de Madrid
Madrid, Spain
February 16, 2024
ABSTRACT
Adversarial attacks represent a substantial challenge in Natural Language Processing (NLP). This
study undertakes a systematic exploration of this challenge in two distinct phases: vulnerability
evaluation and resilience enhancement of Transformer-based models under adversarial attacks.
In the evaluation phase, we assess the susceptibility of three Transformer configurations—encoder-
decoder, encoder-only, and decoder-only setups—to adversarial attacks of escalating complexity
across datasets containing offensive language and misinformation. Encoder-only models manifest a
performance drop of 14% and 21% in offensive language detection and misinformation detection
tasks respectively. Decoder-only models register a 16% decrease in both tasks, while encoder-decoder
models exhibit a maximum performance drop of 14% and 26% in the respective tasks.
The resilience-enhancement phase employs adversarial training, integrating pre-camouflaged and
dynamically altered data. This approach effectively reduces the performance drop in encoder-only
models to an average of 5% in offensive language detection and 2% in misinformation detection
tasks. Decoder-only models, occasionally exceeding original performance, limit the performance
drop to 7% and 2% in the respective tasks. Encoder-decoder models, albeit not surpassing the original
performance, can reduce the drop to an average of 6% and 2% respectively.
These results suggest a trade-off between performance and robustness, albeit not always a strict one,
with some models maintaining similar performance while gaining robustness. Our study, which
includes the adversarial training techniques used, has been incorporated into an open-source tool
that will facilitate future work in generating camouflaged datasets. Although our methodology
shows promise, its effectiveness is subject to the specific camouflage technique and nature of data
encountered, emphasizing the necessity for continued exploration.
Keywords Natural Language Processing · Robustness · Adversarial attack
arXiv:2402.09874v1 [cs.CL] 15 Feb 2024

Camouflage is all you need A PREPRINT
1 Introduction
The rapid advancement of Artificial Intelligence (AI) and its increasing ubiquity in various domains have underscored
the importance of ensuring the robustness and reliability of machine learning models [
1
,
2
]. A particular area of concern
lies in the field of Natural Language Processing (NLP) [
3
], where Transformer-based language models have proven to
be very effective in tasks ranging from sentiment analysis and text classification to question answering [4, 5].
One of the novel and key challenges in NLP relates to adversarial attacks, where subtle modifications are made to
input data to fool the models into making incorrect predictions [3, 6]. A relevant example of this concept is the use of
word camouflage techniques. For instance, the phrase "Word camouflage" can be subtly altered to “W0rd cam0uflage"
or “VV0rd cam0ufl4g3." While these changes are often unnoticeable to a human reader, they can lead a machine
learning model to misinterpret or misclassify the input [
7
]. This raises substantial ethical issues around misinformation
dissemination, content evasion, and the potential for AI systems to be exploited for malicious intent [8, 9].
Real-world implications of these attacks are increasingly evident, with numerous instances of adversarial attacks
compromising online content moderation systems, leading to the spread of harmful content [
10
]. Existing methods to
counter such adversarial attacks have limitations and often focus on post-attack detection [
11
,
12
], failing to proactively
prevent the occurrence of such attacks. Additionally, these methods often struggle with text data which is discrete in
nature, making it challenging to apply perturbation methods that were originally designed for continuous data like
images [2, 3, 13].
This study introduces a comprehensive methodology to evaluate and strength the resilience of Transformer-based
language models to camouflage adversarial attacks. We examine the vulnerability and robustness of distinct Transformer
configurations—encoder-decoder, encoder-only, and decoder-only—in two use-cases involving offensive language and
false information datasets.
The research adopts a proactive defense strategy of adversarial training, which incorporates camouflaged data into the
training phase. This is accomplished either by statically camouflaging the dataset or by dynamically altering it during
training. A key contribution is the development of an open-source tool
1
that generates various versions of camouflaged
datasets, offering a range of difficulty levels, camouflage techniques, and proportions of camouflaged data.
The evaluation of model vulnerability is based on an unbiased methodology, drawing from significant literature
references [
14
,
15
,
16
,
17
,
18
] and using AugLy [
19
], a data augmentation library, for external validation. This approach
helps ensure that our assessment of model weakness accurately reflects real-world content evasion and misclassification
techniques.
In addressing the the current gaps in the field [
3
], our research provides insights into three critical chal-
lenges—perceivability (the extent to which adversarial changes are noticeable), transferability (the ability of an attack
to be effective across different models), and automation (the ability to generate adversarial examples automatically) of
camouflaged adversarial examples.
Preliminary results indicate considerable susceptibility across various Transformer configurations, with performance
drops reaching up to 14% in offensive language detection and 26% in misinformation detection tasks, highlighting the
salient requirement for robustness augmentation.
In addition to identifying these vulnerabilities, the research explores the enhancement of models against such threats.
Employing adversarial training methodologies that amalgamate both pre-camouflaged and dynamically altered data, the
study uncovers promising avenues for resilience improvement. However, the effectiveness of the approach is influenced
by several variables, including the complexity of the camouflage technique employed and the nature and distribution of
data encountered by the model, thus emphasising the urgent need for further research in this domain.
The research paper is organised as follows: Section 2 reviews pertinent literature, illuminating the gaps in existing
methodologies that this research endeavours to address. Section 3 provides a detailed outline of the methodology
employed to develop word camouflage adversarial attacks, while Section 4 explicates the procedure undertaken for
enhancing and evaluating the resilience of Transformer models. Section 5 presents empirical findings from each stage
of the study, evidencing the impact of adversarial attacks on naive Transformer models, alongside the efficacy of
the adversarial fine-tuning approach implemented. Finally, Section 6 offers an in-depth discussion of the research’s
implications, ethical considerations, and limitations, concluding with recommendations for future exploration.
1
Omitted for anonymity reasons.
2

Camouflage is all you need A PREPRINT
2 Background and Related Work
This section will cover the various aspects of adversarial attacks within the field of Natural Language Processing
(NLP). Topics discussed will include the definition of adversarial attacks, the taxonomy of attacks, the measurement of
perturbations, and the evaluation metrics for attack effectiveness. It will also explore the impact of these attacks on
deep learning models in NLP tasks and potential solutions and defenses against these attacks.
2.1 Conceptual Aspects of Adversarial Attacks in NLP
Adversarial attacks constitute a significant challenge to deep learning models, as they introduce minimal, often
imperceptible, changes to input data with the aim of triggering incorrect model outputs [3, 13, 20].
Adversarial attacks fall into two main categories: white-box and black-box attacks. In white-box attacks, attackers
possess complete access to the model’s architecture, parameters, loss functions, activation functions, and input/output
data, allowing them to craft more precise and effective attacks [
3
,
21
,
22
,
23
]. Conversely, black-box attacks operate
under limited knowledge, with attackers only having access to the model’s inputs and outputs. Despite the constraints,
these attacks can still induce incorrect model outputs and are more reflective of real-world scenarios [3, 6].
Perturbation measurements, controlling the magnitude and direction of alterations, and evaluation metrics, like accuracy
and F1 score, allow for a standardized comparison of different adversarial attacks’ impact on model performance [
3
,
13
,
7, 12].
Although adversarial threats persist, several defenses have been proposed, including adversarial training, defensive
distillation, feature squeezing, and input sanitization [
20
,
24
,
25
]. However, these defenses remain susceptible to more
sophisticated attacks [3].
These challenges are particularly relevant for Transformer models given their broad usage in NLP tasks, making the
investigation of their susceptibility to adversarial attacks and potential defenses highly significant.
2.2 Transformers and Their Significance
Transformer models have revolutionized Natural Language Processing (NLP), offering exceptional performance across a
variety of tasks and thereby becoming a leading model in the field [
5
,
26
,
4
]. Unlike their predecessors, Recurrent Neural
Networks (RNNs) and Convolutional Neural Networks (CNNs), Transformers employ attention mechanisms, allowing
for simultaneous input processing and resulting in enhanced performance on context-dependent tasks [27, 28, 29, 30].
Transformer models can adopt multiple configurations. Encoder-decoder models are suitable for tasks like machine
translation, requiring the generation of output sequences based on input understanding [
4
,
31
]. Encoder-only models,
such as BERT, focus on input representations, ideal for tasks like text classification [
32
]. Decoder-only models, like GPT,
facilitate sequence generation based on a given context, useful in text generation or language translation tasks [
33
,
34
].
In the face of adversarial attacks, the complexity of Transformer models presents both challenges and opportunities [
3
].
While their superior performance can lead to vulnerabilities, their configurational flexibility could provide potential
defense strategies, making the understanding of their architecture essential in the context of adversarial attacks.
2.3 Previous Works
The exploration of Deep Neural Networks (DNNs) for text data has lagged behind image data, though recent research
has begun to reveal DNN vulnerabilities in text-based tasks [
3
,
24
]. Studies have shown that carefully crafted adversarial
text samples can manipulate DNN-based classifiers [3].
Significant work, such as those by Liang et al.[
35
] and Cheng et al.[
21
], has been done in the white-box attack domain,
demonstrating the feasibility of misleading DNN text classifiers with adversarial samples. In another study, Blohm et
al.[
36
] focused on comparing the robustness of convolutional and recurrent neural networks via a white-box approach.
Guo et al.[
37
] offered a white-box attack method for transformer models, but their approach neglected token insertions
and deletions, compromising the naturalness of the adversarial examples.
Black-box adversarial attacks have gained attention recently. Noteworthy work by Maheshwary et al.[
38
] presented an
attack strategy that generated high-quality adversarial examples with a high success rate. The work of Gil et al.[
39
]
distilled white-box attack experience into a neural network to expedite adversarial example generation. Similarly, Li et
al. [
40
] proposed a black-box adversarial attack for named entity recognition tasks, demonstrating the importance of
understanding black-box attacks for developing robust models.
3

Camouflage is all you need A PREPRINT
Naïve Model Camouflaged Model**
Original Training
Data
⋯
Transformer
Testing
Test Level 1 Level 2 Level 3
v1* v2
v1 v2
v1 v2
p
Training Data
p
%
Randomly
Camouflaged
⋯
Transformer
Testing
v1 v2
v1 v2
v1 v2
p
= {10, 25, 50, 75, 100}
**Approach 1 → Static Camouflage
**Approach 2 → Dynamic Camouflage
* Level 1 v1
p
= 10%
p
= 25%
p
= 50%
p
= 100%
p
= 75%
Test Level 1 Level 2 Level 3
Figure 1: Methodology for training and evaluating Transformed models to assess word camouflage robustness. Left side:
naive model trained on original dataset and tested on various versions (Te, C-Te-Lvl1/2/3) with different camouflaged
keywords and percentages (p) of modified instances as highlighted in (*). Right side: Camouflaged models trained
on data with mixed random level modifications, developed for different percentages (p) of modifications. (**) Two
approaches highlighted: Approach 1 with pre-camouflaged training data and Approach 2 with on-the-fly data camouflage
during training.
Adversarial attacks have profound real-world implications, ranging from security risks in autonomous driving [
41
] to
societal structures like voter dynamics [
42
] and social networks [
43
,
44
]. These examples underscore the importance
of addressing adversarial attack vulnerabilities across domains, emphasizing naturalness, black-box evaluation, and
flexibility.
2.4 Adressing Open Issues
Several challenges persist in the field of adversarial attacks on text data [
3
]. Primarily, creating textual adversarial
examples is complex due to the need to maintain syntax, grammar, and semantics, which makes fooling natural language
processing (NLP) systems difficult [
2
,
3
,
13
]. Transferability needs a deeper understanding across different architectures
and datasets, and automating adversarial example generation remains difficult. Additionally, with the advent of new
architectures like generative models and those with attention mechanisms, their vulnerability to adversarial attacks
needs to be explored.
To address these issues, the paper proposes an approach focusing on new architectures, transferability, and automation in
black-box adversarial attacks. The researchers explore a range of Transformer model configurations, study transferability
across different datasets and architectures, and design an automated method for generating adversarial examples. They
rely on literature references for unbiased evaluation [
14
,
15
,
16
,
17
,
18
] and AugLy [
19
] for external validation. The
focus on black-box adversarial attacks helps simulate real-world scenarios, contributing to enhanced security in areas
like social networks and content moderation.
3 Methodology
This section starts with Phase I, emphasizing the ‘Camouflaging Techniques’ and ‘Camouflage Difficulty Levels’ in the
development and evaluation of adversarial attacks (subsections 3.1.1 and 3.1.2). Phase II then explores the ‘Fine-tuning
Approaches’ (subsection 3.2.1) to enhance model resilience against word camouflage attacks, followed by an ‘External
Validation’ to ensure robustness (subsection 3.2.2).
4

Camouflage is all you need A PREPRINT
Table 1: Parameters defining the levels of word camouflage
complexity considered. The table displays three levels of
complexity, with each level having two versions based on
the max_top_n parameter set to either 5 or 20 for versions 1
and 2, respectively. This parameter defines the maximum
number of keywords to extract and camouflage. These levels
and versions illustrate the diverse configurations for eval-
uating the robustness of language models against various
camouflage techniques.
Parameters
Level 1 max_top_n=[5, 20]
leet_punt_prb=0.9
leet_change_prb=0.8
leet_change_frq=0.8
leet_uniform_change=0.5
method=["basic_leetspeak"]
Level 2 max_top_n=[5,20]
leet_punt_prb=0.9
leet_change_prb=0.5
leet_change_frq=0.8
leet_uniform_change=0.6
punt_hyphenate_prb=0.7
punt_uniform_change_prb=0.95
punt_word_splitting_prb=0.8
method=[ïntermediate_leetspeak "punct_camo"]
Level 3 max_top_n=[5,20]
leet_punt_prb=0.4
leet_change_prb=0.5
leet_change_frq=0.8
leet_uniform_change=0.6
punt_hyphenate_prb=0.7
punt_uniform_change_prb=0.95
punt_word_splitting_prb=0.8
inv_max_dist=4
inv_only_max_dist_prb=0.5
method=[ädvanced_leetspeak "punct_camo ïnv_camo"]
Table 2: A description of the parameters consid-
ered during the training of the models for word
camouflaged Named Entity Recognition with
Spacy.
learning rate
initial_rate = 0.00005
total_steps = 20000
scheduler = warmup_linear
warmup_steps = 250
epochs
max_epochs = 0
max_steps = 20000
patience = 1600
accumulate_gradient 3
optimizer
AdamW
beta = 10.9
beta2 = 0.999
eps = 1e-8
grad_clip = 1
l2 = 0.01
l2_is_weight_decay = true
eval_frequency 200
dropout 0.1
3.1 Phase I: Evaluating the Impact of Word Camouflage on Transformer Models
3.1.1 Camouflaging Techniques
The study employs the “pyleetspeak" Python package, developed based on recent research [
45
], for generating realistic
adversarial text samples. This package applies three distinct text camouflage techniques, prioritizing semantic keyword
extraction over random selection, thereby providing a more realistic representation of word camouflage threats. Selected
for their relevance and varied complexity in adversarial attacks, these techniques offer a robust evaluation of model
resilience. These techniques are:
•
Leetspeak: This technique involves substituting alphabet characters with visually analogous symbols or
numbers, creating changes that can range from basic to highly intricate. As an illustration, Offensive" could be
altered to 0ff3ns1v3" with vowel and specific consonant replacements.
•
Punctuation Insertion: This method alters text by introducing punctuation symbols to create visually similar
character strings. Punctuation can be inserted at hyphenation points or between any two characters. For
example, “fake news" could be camouflaged as “f-a-k-e n-e-w-s".
•
Syllable Inversion: This technique, less commonly used, camouflages words by rearranging their syllables.
For instance, “Methodology" could be altered to “Me-do-tho-lo-gy" by inverting the syllables in the word.
The use of these techniques helps to perform a thorough investigation of the Transformer models’ resilience to different
kinds of adversarial attacks.
5

Camouflage is all you need A PREPRINT
Camouage is all you need A Preprint
Table 3: Comparison of original and camouaged text examples from the Oen SemEval 2019 and Constraint
datasets. The table presents examples of three levels of camouage by the tool introduced in this study, as
well as an example from the AugLy library for external validation with unseen modications. Each level
represents increasing complexity of camouage.
Oen SemEval Constraint
Original 6 ANTIFA ATTACKED COPS, ARRESTED
AT RALLY IN DENVER, MEDIA BLACKOUT
URL
FDA chief Hahn comments about con-
valescent plasma for #COVID-19 pa-
tients stirred controversy and a shake
up at the agency.
Level 1 6 ANTįFA ATTACKED CʘPS, ăRRƸST3D
AT RALLY IN DēNVėR, MEDĩ∀ BLACKOUT
URL
FDą ch!ěf Hahn comments about
convalescent plasma for #COVID-19
pȁtïƸnts stirred controversy and a
shake up at the ∀gency.
Level 2 6 Aͷ'T1FA ATTACKED :ć:O:P:ś:,
āR]RͼϟTͼĐ AT RALLY IN |)ƐN;VƐR,
ɱĕĐ!@ BLACKOUT URL
%F%D%A cĥįȇf |-|Ʌhℕ comments
about convalescent plasma for #CȱVID-
19 _|_>_a_t_i_Ɛ_n_t_s stirred contro-
versy and a shake up at the Ƌgeͷcy
Level 3 6@Д@η@ȶ@į@ſ@Д ATTACKED COPS,
ąR>RℯSTƸđAT RALLY IN DēN√ēR,
[)1A]V[E BLACKOUT URL
/=(|ä'ch][Ə'f Ha'hn c'omme'nts 'abou't
co'nval'esce'nt p'lasm'a fo'r #C'OVID'-
19 ℙⱥŦïěnŦs sti'rred' con'trov'ersy' and'
a s'hake' up 'at t'he a g ƹ n č y.
AugLy 6 AN...ṫIFA... ATT...ACKE...D CO...PS,
...AŕRE...STEȡ... AT ...RẰLL...Y IN...
...U/2L
FDA chief Hahn ĆommenṮs about con-
valescent plasma foℜ#CO∨ID-19 pa-
tients stiɌrĒd controversy and a shake
uƿ aț the agency.
Including all three levels of camouage in the training of these models aims to enhance their ability to
generalize across a variety of adversarial conditions. However, given the potential impact of camouage
frequency on training, we maintain the percentage of camouaged instances consistent for each individual
model.
Furthermore, for each Camouaged Model, we employ two dierent ne-tuning strategies, as depicted in
Figure 1:
•
Static Modication: This approach involves camouaging the training dataset prior to model
training. The benet of this method lies in its simplicity and predictability, as the dataset remains
consistent throughout the training process. However, this may limit the model’s ability to adapt to
new or varying types of camouage not represented in the initial dataset.
•
Dynamic Modication: In contrast, this method involves camouaging the training dataset
‘on-the-y’, introducing changes during the training process itself. This allows the model to be
exposed to a wider variety and unpredictability of camouage techniques, potentially improving its
ability to generalize and adapt. The trade-o, however, is a more complex and computationally
demanding training process.
Together, these dierent training and evaluation strategies provide a comprehensive approach to understanding
the susceptibility of natural language processing models to word camouage, and the potential strategies for
improving their robustness. The parameters employed to the ne-tuning approaches can be found at 2.
3.2.2 External Validation
The AugLy library [
19
], developed by Meta AI, is used as an instrument of external validation in order to
ensure the objectiveness and applicability of our evaluations. By generating an auxiliary test dataset, we
can re-arm our evaluations on model resilience against word camouage. This library extends a distinctive
approach of random text modications, including letter substitutions with analogous Unicode or non-Unicode
7
Figure 2: Comparison of original and camouflaged text examples from the Offen SemEval 2019 and Constraint datasets.
The table presents examples of three levels of camouflage by the tool introduced in this study, as well as an example
from the AugLy library for external validation with unseen modifications. Each level represents increasing complexity
of camouflage.
3.1.2 Camouflage Difficulty Levels
Adversarial camouflage attacks in this study are systematically varied across three parameters: complexity level, word
camouflage ratio (amount of words camouflaged within a data instance), and instance camouflage ratio (the proportion
of camouflaged instances within a test dataset). This approach enables a comprehensive assessment of the models’
susceptibility to these attacks. Each complexity level involves specific parameters, as detailed in Table 1. Examples of
each level are depicted in Table 2.
•
Level 1 serves as a starting point and is quite readable and understandable. It introduces minor changes to the
text, primarily focusing on simple character substitutions, such as replacing every vowel with a number or
similar symbol.
•
Level 2 increases the complexity of modifications. It introduces extended and complex character substitutions,
punctuation injections, and simple word inversions. It extends substitutions to both vowels and consonants,
introducing also readable symbols from other alphabets that closely resemble regular alphabet characters.
•
Level 3 is the most complex tier. It combines techniques from the previous two levels but intensifies the use of
punctuation marks, introduces more character substitutions, and incorporates inversions, and mathematical
symbols are also incorporated making the text even more challenging to comprehend.
For each complexity level, two versions are produced. These versions, known as ‘v1’ and ‘v2’, represent different word
camouflage ratios, camouflaging 15% and 65% of words per text, respectively. These ratios were derived from the
statistical distribution of text lengths in the employed datasets.
These three complexity levels emulate real-world adversarial camouflage attacks, facilitating a methodical progression
from low to high complexity, and thus, allowing a detailed evaluation of model robustness against incrementally
challenging adversarial scenarios.
Regarding, instance camouflage ratio, as depicted in Figure 1, the tests systematically introduce varying levels and
percentages of camouflage into the data instances. Starting from an original test set (Te), 30 additional tests are
6

Camouflage is all you need A PREPRINT
generated across three difficulty levels, each with two word camouflage ratio versions (v1 and v2), and five different
percentages of camouflaged instances (10%, 25%, 50%, 75%, and 100%). This structure, totalling 31 tests, provides a
robust framework for assessing the impact of increasing prevalence and complexity of camouflage techniques. Further
discussion on this methodology is covered in Section 4.3.
This systematic approach allows a granular evaluation of word camouflage adversarial attacks, providing insights into
their implications and potential countermeasures.
3.2 Phase II: Improving Resilience Against Word Camouflage Attacks
3.2.1 Fine-tuning Approaches
In our study, as depicted in Figure 1, we train and evaluate two distinct sets of models for each task: ‘Naive Models’
and ‘Camouflaged Models’.
The Naive Models represent a baseline approach. These models are trained on the original, unaltered datasets, thus
reflecting traditional methods of natural language processing model training. Once training is complete, these models
are then evaluated across the 31 different tests we defined earlier, which incorporate varying degrees and proportions of
word camouflage.
On the other hand, the Camouflaged Models integrate adversarial data during their training phase. These models are
trained on datasets that are modified to include instances of word camouflage, drawn randomly from the three levels
of difficulty we previously described. Notably, a distinct Camouflaged Model is trained for each possible percentage
of camouflaged data instances (10%, 25%, 50%, 75%, and 100%). This approach allows us to investigate how the
distribution or frequency of camouflaged instances within the training data may affect the model’s robustness and
performance.
Including all three levels of camouflage in the training of these models aims to enhance their ability to generalize
across a variety of adversarial conditions. However, given the potential impact of camouflage frequency on training, we
maintain the percentage of camouflaged instances consistent for each individual model.
Furthermore, for each Camouflaged Model, we employ two different fine-tuning strategies, as depicted in Figure 1:
•
Static Modification: This approach involves camouflaging the training dataset prior to model training. The
benefit of this method lies in its simplicity and predictability, as the dataset remains consistent throughout the
training process. However, this may limit the model’s ability to adapt to new or varying types of camouflage
not represented in the initial dataset.
•
Dynamic Modification: In contrast, this method involves camouflaging the training dataset ‘on-the-fly’,
introducing changes during the training process itself. This allows the model to be exposed to a wider variety
and unpredictability of camouflage techniques, potentially improving its ability to generalize and adapt. The
trade-off, however, is a more complex and computationally demanding training process.
Together, these different training and evaluation strategies provide a comprehensive approach to understanding the
susceptibility of natural language processing models to word camouflage, and the potential strategies for improving
their robustness. The parameters employed to the fine-tuning approaches can be found at 2.
3.2.2 External Validation
The AugLy library [
19
], developed by Meta AI, is used as an instrument of external validation in order to ensure
the objectiveness and applicability of our evaluations. By generating an auxiliary test dataset, we can re-affirm our
evaluations on model resilience against word camouflage. This library extends a distinctive approach of random text
modifications, including letter substitutions with analogous Unicode or non-Unicode characters, punctuation insertions
and font alterations. While these manipulations are based on random selection, instead of keyword extraction as in our
methodology, they nonetheless simulate potential evasion techniques, providing a valuable counterpoint to our stratified
camouflage techniques.
AugLy diverge from the ‘pyleetspeak’ package implemented in our research, which select word to be camouflaged
based on semantic importance. Furthermore, AugLy exhibits a limited degree of flexibility in terms of user control and
omits features such as word inversion and modification tracking.
Nevertheless, as an instrument of external validation, AugLy assumes a crucial role, especially when compared with
the three-tier complexity levels. Comparative analysis with AugLy facilitates the identification of potential model
7

Camouflage is all you need A PREPRINT
vulnerabilities and ensures unbiased results, ensuring a comprehensive defense strategy. This approach guarantees
rigorous model evaluation and improves real-world performance resilience.
4 Experimental Setup
This section outlines the critical components of the research design. Subsection 4.1 details the specific architectures
employed in the study, while the ’Data’ subsection 4.2 describes the datasets used for adversarial sample creation and
model training and evaluation. Lastly, subsection 4.3 establishes the evaluation metrics and procedures for determining
model resilience against adversarial attacks.
4.1 Transformer Models
In this investigation, three distinct Transformer models are employed, each representing a unique configuration: encoder-
only, decoder-only, and encoder-decoder. This selection facilitates the comparison of performance and resilience to
adversarial attacks under diverse operational conditions.
BERT (bert-base-uncased) [
32
] serves as the encoder-only model. Renowned for its wide application and being among
the most downloaded models on HuggingFace
2
, BERT provides an ideal case for examining the potential susceptibility
of prevalent models to adversarial onslaughts and word camouflage. Pretrained with the primary objectives of Masked
Language Modeling (MLM) and Next Sentence Prediction (NSP), BERT boasts approximately 110M parameters.
The mBART model (mbart-large-50) [
46
] functions as the encoder-decoder paradigm. An extension of the original
mBART model, it supports 50 languages for multilingual machine translation models. Its "Multilingual Denoising
Pretraining" objective introduces noise to the input text, potentially augmenting its robustness against adversarial attacks.
Developed by Facebook, this model encapsulates over 610M parameters.
Lastly, Pythia (pythia-410m-deduped) [
47
], forming part of EleutherAI’s Pythia Scaling Suite, is harnessed. With its
training on the Pile [
48
], a dataset recognized for its diverse range of English texts, it offers a fitting choice for analyzing
model resilience to the often biased and offensive language pervasive on the internet. Comprising 410M parameters, it
is well-equipped for this study.
4.2 Data
The study utilizes two primary datasets, OffensEval [
49
] and Constraint [
50
], representing distinct aspects of online
behavior. OffensEval, part of the SemEval suite, consists of over 14,000 English tweets focusing on offensive language
in social media. On the other hand, Constraint pertains to the detection of fake news related to COVID-19 across various
social platforms, comprising a collection of 10,700 manually annotated posts and articles.
These datasets underscore the significance of combatting offensive language and misinformation, especially during
critical times like a pandemic. They provide a solid foundation for examining the resilience of Transformer models to
adversarial attacks and gauging the efficacy of camouflage techniques in evading detection.
To ensure data quality and reliability, several preprocessing steps were undertaken. These include eliminating duplicates,
filtering out instances with fewer than three characters, preserving the original text case, and verifying the balance of
the binary classes across both datasets. This balance verification is pivotal to ensure a fair assessment of camouflage
techniques across different classes and avoid bias introduced by class imbalances.
Post-preprocessing, the datasets were divided into training, validation, and test sets, ensuring a comprehensive and
balanced evaluation. For OffensEval and Constraint, the training set comprised 11,886 and 6,420 instances, respectively,
with appropriate allocations for validation and testing.
4.3 Evaluating Robustness
For the evaluation of model performance, the F1-macro score is used. Despite the datasets being balanced, the choice of
F1-macro score offers a more rigorous measure that enables the effective isolation of the impact of word camouflage
techniques on performance and minimizes any potential bias due to class distribution.
A comprehensive experimental setup is implemented, encompassing 31 internal tests and an external test from AugLy.
This detailed framework facilitates an in-depth assessment of how increasing complexity of camouflage techniques
influence model performance and the practical application of the results.
2
https://huggingface.co/models?pipeline_tag=fill-mask&sort=downloads
8

Camouflage is all you need A PREPRINT
Table 3: Encoder-Only Transformer models original performance and performance reduction across camouflage levels,
and AugLy. Models exceeding Naive ones are marked (*), with the least impacted by camouflage highlighted in bold.
Model F1-Macro
Performance Reduction
Levels
AugLy
1.1 1.2 2.1 2.2 3.1 3.2 Avg
Naïve 0.7782 2% 6% 6% 13% 7% 14% 8% 10%
10-static 0.7870* 2% 5% 6% 11% 6% 13% 7% 9%
25-static 0.7852* 2% 5% 6% 10% 5% 12% 6% 9%
50-static 0.7887* 2% 7% 5% 11% 5% 11% 7% 8%
75-static 0.7962* 3% 7% 5% 9% 5% 10% 7% 8%
100-static 0.4189 - - - - - - - -
10-dynamic 0.7828* 3% 7% 5% 11% 5% 13% 7% 10%
25-dynamic 0.7947* 4% 8% 7% 12% 7% 13% 8% 10%
50-dynamic 0.7791 3% 8% 5% 9% 6% 9% 7% 8%
75-dynamic 0.7945* 3% 6% 5% 9% 6% 9% 6% 7%
100-dynamic 0.7527 0% 4% 3% 8% 4% 10% 5% 5%
(a) Encoder-only OffensEval comparative performance
Model F1-Macro
Performance Reduction
Levels
AugLy
1.1 1.2 2.1 2.2 3.1 3.2 Avg
Naïve 0.9677 4% 14% 7% 17% 11% 21% 12% 9%
10-static 0.9649 1% 3% 1% 6% 3% 6% 3% 7%
25-static 0.9649 1% 3% 2% 5% 2% 5% 3% 6%
50-static 0.9602 1% 3% 2% 4% 2% 4% 3% 4%
75-static 0.9517 1% 2% 1% 3% 2% 4% 2% 7%
100-static 0.9443 1% 1% 1% 3% 1% 3% 2% 8%
10-dynamic 0.9629 2% 3% 3% 5% 3% 6% 4% 6%
25-dynamic 0.9653 2% 3% 1% 5% 3% 5% 3% 6%
50-dynamic 0.9569 1% 2% 2% 4% 2% 5% 3% 7%
75-dynamic 0.9569 1% 2% 2% 3% 2% 4% 2% 6%
100-dynamic 0.9427 1% 1% 1% 2% 1% 3% 2% 5%
(b) Encoder-only Constraint comparative performance
Model robustness is assessed by the degree of performance reduction when models are evaluated on camouflaged test
datasets at varied levels, relative to their performance on the original test dataset. The degree of performance reduction
serves as a systematic measure of model resilience against adversarial attacks and illuminates how model performance
deteriorates as difficulty levels increase and percentage of modified data escalates.
5 Experiment Results and Discussion
5.1 Phase I: Assessing Transformer Models’ Susceptibility to Word Camouflage
Table 4: Decoder-Only Transformer models original performance and performance reduction across camouflage levels,
and AugLy. Models exceeding Naive ones are marked (*), with the least impacted by camouflage highlighted in bold.
Model F1-Macro
Performance Reduction
Levels
AugLy
1.1 1.2 2.1 2.2 3.1 3.2 Avg
Naïve 0.7185 7% 15% 8% 16% 8% 16% 12% 11%
10-static 0.7159 8% 12% 9% 13% 8% 14% 11% 14%
25-static 0.6906 4% 11% 5% 12% 5% 11% 8% 8%
50-static 0.6750 4% 9% 5% 10% 6% 10% 7% 7%
75-static 0.6249 7% 9% 5% 7% 4% 8% 7% 8%
100-static 0.4309 1% 1% 1% 1% 1% 1% 1% 0%
10-dynamic 0.7351* 6% 13% 6% 15% 7% 15% 10% 9%
25-dynamic 0.7368* 5% 12% 7% 17% 9% 13% 11% 10%
50-dynamic 0.6636 3% 9% 4% 10% 5% 10% 7% 4%
75-dynamic 0.7029 7% 11% 8% 11% 7% 11% 9% 10%
100-dynamic 0.5932 2% 4% 3% 8% 3% 6% 5% 5%
(a) Decoder-only OffensEval comparative performance
Model
Test
F1-Macro
Performance Reduction
Levels
1.1 1.2 2.1 2.2 3.1 3.2 Avg AugLy
Naïve 0.9380 4% 10% 8% 15% 7% 16% 10% 7%
10-static 0.9270 3% 11% 4% 12% 4% 11% 7% 8%
25-static 0.9046 3% 6% 4% 9% 4% 9% 6% 6%
50-static 0.8975 2% 5% 2% 6% 3% 7% 4% 4%
75-static 0.8700 3% 6% 3% 6% 3% 6% 5% 5%
100-static 0.7935 1% 1% 1% 1% 1% 2% 1% 2%
10-dynamic 0.9340 3% 7% 4% 8% 4% 9% 6% 8%
25-dynamic 0.9198 3% 9% 4% 12% 6% 11% 7% 6%
50-dynamic 0.8752 2% 5% 2% 6% 3% 6% 4% 4%
75-dynamic 0.8958 1% 3% 2% 3% 2% 4% 2% 4%
100-dynamic 0.3436 - - - - - - - -
(b) Decoder-only Constraint comparative performance
The initial phase of the study is dedicated to investigating the vulnerability of Naive transformer models to adversarial
attacks conducted through word camouflage. These models, having been trained on original datasets without prior
exposure to word camouflage, are evaluated using the OffensEval and Constraint tasks. This assessment includes
all three transformer configurations - Encoder-only, Decoder-only, and Encoder-Decoder, each being scrutinised
independently.
A consistently emerging trend across all tasks and model configurations is the significant reduction in performance of
Naive models as the complexity of camouflage levels intensifies.
As an illustration, in the OffensEval task, the Encoder-only Naive model’s performance reduces by an average of
8%, starting from a 2% decrease at Level 1 and peaking at a 14% decrease at Level 3 (as depicted in Table 3a). The
Decoder-only Naive models showcase a similar pattern, albeit with a steeper average performance decline of 12%,
9

Camouflage is all you need A PREPRINT
Table 5: Comparative Performance and Resilience of Encoder-Decoder Transformer Models to Word Camouflage
on the Offensive Language Task from (a) OffensEval and (b) Constraint. The ’Test F1-Macro’ column indicates the
F1-Macro score achieved by each model on the original, non-camouflaged Test dataset. Models outperforming the
Naive model are marked with an asterisk (*). The ’Weakness’ columns report the percentage reduction in performance
on different levels of camouflaged Test datasets compared to the original Test dataset. In these columns, the model
with the lowest percentage reduction is highlighted in bold, and the model with the greatest weakness is in italics. The
’AugLy’ column indicates model performance on the AugLy camouflaged dataset.
Model F1-Macro
Performance Reduction
Levels
1.1 1.2 2.1 2.2 3.1 3.2 Avg AugLy
Naïve 0.7436 6% 12% 7% 15% 7% 14% 10% 7%
10-static 0.7331 4% 9% 6% 10% 7% 13% 8% 10%
25-static 0.6330 4% 5% 3% 7% 3% 7% 5% 5%
50-static 0.7293 4% 10% 5% 9% 5% 10% 7% 15%
75-static 0.7282 2% 9% 3% 10% 4% 9% 6% 9%
100-static 0.6841 2% 8% 4% 9% 4% 9% 6% 7%
10-dynamic 0.7234 6% 11% 6% 12% 7% 13% 9% 11%
25-dynamic 0.7221 2% 9% 3% 15% 2% 11% 7% 3%
50-dynamic 0.7138 5% 9% 4% 10% 4% 11% 7% 7%
75-dynamic 0.6429 3% 4% 3% 7% 3% 7% 4% 9%
100-dynamic 0.6489 2% 3% 1% 3% 2% 5% 3% 5%
(a) Encoder-Decoder OffensEval comparative performance
Model F1-Macro
Performance Reduction
Levels
1.1 1.2 2.1 2.2 3.1 3.2 Avg AugLy
Naïve 0.9568 5% 20% 7% 24% 10% 26% 15% 9%
10-static 0.9555 3% 7% 3% 8% 3% 10% 6% 7%
25-static 0.9415 2% 4% 2% 5% 2% 5% 3% 5%
50-static 0.9537 1% 2% 1% 3% 1% 3% 2% 7%
75-static 0.9489 1% 3% 1% 3% 1% 3% 2% 5%
100-static 0.9140 1% 2% 1% 3% 1% 3% 2% 4%
10-dynamic 0.9475 2% 5% 2% 6% 3% 7% 4% 5%
25-dynamic 0.9523 2% 4% 3% 6% 4% 6% 4% 6%
50-dynamic 0.9406 1% 4% 2% 5% 2% 5% 3% 4%
75-dynamic 0.9241 1% 3% 2% 4% 2% 4% 3% 4%
100-dynamic 0.9140 1% 2% 1% 3% 1% 3% 2% 4%
(b) Encoder-Decoder Constraint comparative performance
reaching a maximum of 16% at Level 3 (refer to Table 4a). Among all configurations, the Encoder-Decoder model
exhibits the least drastic performance decline, with an average decrease of 10% and a maximum decrease of 10% at
Level 3 (refer to Table 5a).
The same pattern is observed in the Constraint task, with the performance of the Naive models progressively deteriorates
with the escalation of camouflage levels. The Encoder-only model, as presented in Table 3b, endures an average
performance reduction of 12% across all levels, culminating in a 21% reduction at Level 3. In addition to this, the
Decoder-only and Encoder-Decoder configurations experience average performance reductions of 10% and 15%
respectively (Tables 4b, 5b).
These findings underscore the profound impact of increasing complexity on model performance, thereby spotlighting
the inherent weaknesses that various evasion techniques can exploit. Intriguingly, when examining the performance
reduction results for different configurations (refer to Tables 3, 4, and 5), it is evident that all models face heightened
difficulties at Levels 2 and 3 compared to Level 1. Specifically, Level 3 and v2 (featuring an increased ratio of
camouflaged words in each data instance) across all levels prove to be the most challenging.
Particularly, when more camouflaged words are present in a text (represented as v2), the model faces greater challenges
than when fewer words are camouflaged (represented as v1). This conclusion is substantiated by the consistently
elevated performance reduction percentages witnessed across all v2 levels compared to their v1 counterparts. It suggests
that a seemingly straightforward strategy, such as the augmentation of words camouflaged within a text, can substantially
compromise model performance.
Further evidence of this vulnerability is witnessed in the sharp decline in performance of the Naive model in the face
of increasing percentages of camouflaged data. This is clearly depicted in the line plots corresponding to different
Transformer configurations (Figures 3, 4 5, 6, 7 and 8). These figures, representing model performance against varying
percentages of camouflaged data, mimic real-world scenarios. By simulating circumstances wherein users might
employ a spectrum of complexity techniques in word camouflage, these plots offer insightful revelations into how the
widespread implementation of such evasion techniques could influence model performance. They suggest potential
shifts in performance as word camouflage techniques become more prevalent.
Figures 3 and 4 illustrate the Encoder-only Naive model’s performance deterioration as the proportion of camouflaged
data instances elevates within both OffensEval and Constraint tasks. A similar trend is discernible in the Decoder-only
configuration (Figures 5 and 6) and in the Encoder-Decoder configuration (Figures 7 and 8).
In the following section, it will be demonstrated that this performance decline is more pronounced in Naive models
compared to their adversarially-trained counterparts, further underscoring the susceptibility of Naive models to
adversarial attacks.
10

Camouflage is all you need A PREPRINT
Encoder-only - OffensEval Results
Level 1.1 Level 1.2 Level 2.1 Level 2.2 Level 3.1 Level 3.2
0.66
0.68
0.7
0.72
0.74
0.76
10-static-camo 25-static-camo 50-static-camo
75-static-camo Naïve
Static Camouflage - Complexity Level
F1-Macro
(a)
Level 1.1 Level 1.2 Level 2.1 Level 2.2 Level 3.1 Level 3.2
0.66
0.68
0.7
0.72
0.74
0.76
10-dynamic-camo 100-dynamic-camo
25-dynamic-camo 50-dynamic-camo
75-dynamic-camo Naïve
Dynamic Camouflage - Complexity Level
F1-Macro
(b)
C-Te-10 C-Te-25 C-Te-50 C-Te-75 C-Te-100
0.64
0.66
0.68
0.7
0.72
0.74
0.76
0.78
10-static-camo 25-static-camo 50-static-camo
75-static-camo Naïve
Static Camouflage - Instance camouflage ratio
F1-Macro
(c)
C-Te-10 C-Te-25 C-Te-50 C-Te-75 C-Te-100
0.64
0.66
0.68
0.7
0.72
0.74
0.76
0.78
10-dynamic-camo 100-dynamic-camo
25-dynamic-camo 50-dynamic-camo
75-dynamic-camo Naïve
Dynamic Camouflage - Instance camouflage ratio
F1-Macro
(d)
Figure 3: Comprehensive performance comparison of fine-tuned Encoder-only models against naive models in the
Offensive Language task from OffensEval under various conditions. (a) Performance of Pre-camouflaged Models
across different levels. (b) Performance of Var-camouflaged Models across different levels. (c) Performance of Pre-
camouflaged Models across different camouflage percentages. (d) Performance of Var-camouflaged Models across
different camouflage percentages.
Overall, these results bring to light the inherent susceptibility of Naive models across all transformer configurations to
word camouflage attacks, thereby emphasizing the necessity for solutions aimed at fortifying these vulnerabilities.
5.2 Phase II: Enhancing Transformer Robustness Against Word Camouflage Attacks
The motivation behind the second phase of the study was to enhance the robustness of Transformer models against word
camouflage attacks. In the first phase, it was determined that word camouflage attacks could significantly degrade the
performance of the models. This phase aimed to evaluate the effectiveness of various countermeasures, mainly through
the integration of adversarial training strategies using different proportions and methods of data camouflage.
5.2.1 Static vs Dynamic Camouflage
The analysis of the experiments revealed that models trained with a mix of original and statically camouflaged data, up to
a 75% proportion, performed admirably across a variety language detection tasks in both the OffensEval and Constraint
contexts. Specifically, in the OffensEval setting, the Encoder-only model trained with 75% statically camouflaged
data demonstrated improving the performance and decreasing the performance reduction with complexity (see 3a).
However, models trained on completely statically camouflaged datasets saw a significant drop in performance, with the
11

Camouflage is all you need A PREPRINT
Encoder-only - Constraint Results
Level 1.1 Level 1.2 Level 2.1 Level 2.2 Level 3.1 Level 3.2
0.75
0.8
0.85
0.9
0.95
10-static-camo 100-static-camo 25-static-camo
50-static-camo 75-static-camo Naïve
Static Camouflage - Complexity Level
F1-Macro
(a)
Level 1.1 Level 1.2 Level 2.1 Level 2.2 Level 3.1 Level 3.2
0.75
0.8
0.85
0.9
0.95
10-dynamic-camo 100-dynamic-camo
25-dynamic-camo 50-dynamic-camo
75-dynamic-camo Naïve
Dynamic Camouflage - Complexity Level
F1-Macro
(b)
C-Te-10 C-Te-25 C-Te-50 C-Te-75 C-Te-100
0.7
0.75
0.8
0.85
0.9
0.95
10-static-camo 100-static-camo 25-static-camo
50-static-camo 75-static-camo Naïve
Static Camouflage - Instance camouflage ratio
F1-Macro
(c)
C-Te-10 C-Te-25 C-Te-50 C-Te-75 C-Te-100
0.7
0.75
0.8
0.85
0.9
0.95
10-dynamic-camo 100-dynamic-camo
25-dynamic-camo 50-dynamic-camo
75-dynamic-camo Naïve
Dynamic Camouflage - Instance camouflage ratio
F1-Macro
(d)
Figure 4: Comprehensive performance comparison of fine-tuned Encoder-only models against naive models in the
False Information Language task from Constraint under various conditions. (a) Performance of Pre-camouflaged
Models across different levels. (b) Performance of Var-camouflaged Models across different levels. (c) Performance of
Pre-camouflaged Models across different camouflage percentages. (d) Performance of Var-camouflaged Models across
different camouflage percentages.
F1-Macro score falling to 0.4189 across all levels for the ‘100-static’ Encoder-only model (see 3a) and 0.3436 for the
‘100-dynamic’ Decoder-only model (see 4b). This degradation in performance supports the conclusion that a balanced
mix of original and camouflaged data produces superior results.
On the other hand, dynamic camouflage strategies displayed a distinct advantage, with models incorporating these
techniques showing substantial robustness. For instance, a model that dynamically camouflaged 100% of the data during
training managed to avoid performance deterioration and exhibited marked robustness in Table 3a while the 100% static
counterpart stuck. This observation suggests that dynamic camouflage introduces a certain degree of variability and
richness into the training data, which in turn enables the model to learn more effectively and flexibly, although it is still
recommended to include some percentage of original, non-camouflaged data in the training process.
5.2.2 Effect of Camouflage Complexity
An intriguing trend was revealed when examining the relationship between the complexity of camouflage techniques
and model performance. As the camouflage complexity level increased, naive models exhibited more pronounced
performance reduction, as previously observed in Section 5.1 in both the OffensEval and Constraint tasks. This
trend implies an inherent vulnerability of Naive models to heightened complexity in adversarial attacks. However,
12

Camouflage is all you need A PREPRINT
Decoder-only - OffensEval Results
Level 1.1 Level 1.2 Level 2.1 Level 2.2 Level 3.1 Level 3.2
0.58
0.6
0.62
0.64
0.66
10-static-camo 25-static-camo 50-static-camo
75-static-camo Naïve
Static Camouflage - Complexity Level
F1-Macro
(a)
Level 1.1 Level 1.2 Level 2.1 Level 2.2 Level 3.1 Level 3.2
0.54
0.56
0.58
0.6
0.62
0.64
0.66
0.68
0.7
10-dynamic-camo 100-dynamic-camo
25-dynamic-camo 50-dynamic-camo
75-dynamic-camo Naïve
Dynamic Camouflage - Complexity Level
F1-Macro
(b)
C-Te-10 C-Te-25 C-Te-50 C-Te-75 C-Te-100
0.55
0.6
0.65
0.7
10-static-camo 25-static-camo 50-static-camo
75-static-camo Naïve
Static Camouflage - Instance camouflage ratio
F1-Macro
(c)
C-Te-10 C-Te-25 C-Te-50 C-Te-75 C-Te-100
0.55
0.6
0.65
0.7
10-dynamic-camo 100-dynamic-camo
25-dynamic-camo 50-dynamic-camo
75-dynamic-camo Naïve
Dynamic Camouflage - Instance camouflage ratio
F1-Macro
(d)
Figure 5: Comprehensive performance comparison of fine-tuned Decoder-only models against naive models in the
Offensive Language task from OffensEval under various conditions. (a) Performance of Pre-camouflaged Models
across different levels. (b) Performance of Var-camouflaged Models across different levels. (c) Performance of Pre-
camouflaged Models across different camouflage percentages. (d) Performance of Var-camouflaged Models across
different camouflage percentages.
adversarially trained models, particularly those trained with a combination of original and dynamic camouflage data,
such as the ‘75-dynamic-camo’ model, demonstrated lower degrees of reduction (Tables 3, 4 and 5), thereby highlighting
the resilience of adversarially trained models and their enhanced ability to counter advanced camouflage attacks.
5.2.3 Influence of Camouflage Percentage
The analysis also brought to light an inverse relationship between the percentage of camouflaged data and model
performance. As the proportion of camouflaged data in the test set increased, the model’s performance correspondingly
declined. The trend was evident across all models, indicating the importance of considering the expected degree of
camouflage in the actual scenario in order to estimate the impact and to select the most appropriate adversarial training
method.
5.2.4 Architectural Considerations
In addition to the above, an underlying trend emerged from the analysis, which transcended the specific architectural
configurations: training with dynamic camouflage consistently demonstrated superior resilience to adversarial attacks.
13

Camouflage is all you need A PREPRINT
Decoder-only - Constraint Results
Level 1.1 Level 1.2 Level 2.1 Level 2.2 Level 3.1 Level 3.2
0.78
0.8
0.82
0.84
0.86
0.88
0.9
10-static-camo 100-static-camo 25-static-camo
50-static-camo 75-static-camo Naïve
Static Camouflage - Complexity Level
F1-Macro
(a)
Level 1.1 Level 1.2 Level 2.1 Level 2.2 Level 3.1 Level 3.2
0.8
0.82
0.84
0.86
0.88
0.9
10-dynamic-camo 25-dynamic-camo 50-dynamic-camo
75-dynamic-camo Naïve
Dynamic Camouflage - Complexity Level
F1-Macro
(b)
C-Te-10 C-Te-25 C-Te-50 C-Te-75 C-Te-100
0.75
0.8
0.85
0.9
10-static-camo 100-static-camo 25-static-camo
50-static-camo 75-static-camo Naïve
Static Camouflage - Instance camouflage ratio
F1-Macro
(c)
C-Te-10 C-Te-25 C-Te-50 C-Te-75 C-Te-100
0.75
0.8
0.85
0.9
10-dynamic-camo 25-dynamic-camo 50-dynamic-camo
75-dynamic-camo Naïve
Dynamic Camouflage - Instance camouflage ratio
F1-Macro
(d)
Figure 6: Comprehensive performance comparison of fine-tuned Decoder-only models against naive models in the
False Information Language task from Constraint under various conditions. (a) Performance of Pre-camouflaged
Models across different levels. (b) Performance of Var-camouflaged Models across different levels. (c) Performance of
Pre-camouflaged Models across different camouflage percentages. (d) Performance of Var-camouflaged Models across
different camouflage percentages.
This strategy maintained or even enhanced the original model’s performance in many cases, while a high camouflage
percentage brought significant challenges.
When assessing the impact of different model architectures, it was observed that Encoder-only models demonstrated
significant robustness against adversarial attacks when trained with both static and dynamic camouflage techniques. In
the Constraint task, for example, the ‘75-static-camo’ and ‘25-static-camo’ Encoder-only models outperformed their
counterparts on several levels. On the other hand, Encoder-Decoder and Decoder-only setups also showcased improved
performance, thus affirming that adversarial training strategies can be effectively utilized across diverse architectural
setups.
Finally, a key finding was the inverse relationship between the proportion of camouflaged data in the test set and the
model’s performance. As the proportion of camouflaged data increased, there was a noticeable decline in performance
across all models. Thus, striking a balance in data camouflaging is vital: while it can boost generalization, excessive
usage may compromise performance.
14
Camouflage is all you need A PREPRINT
Encoder-Decoder - OffensEval Results
Level 1.1 Level 1.2 Level 2.1 Level 2.2 Level 3.1 Level 3.2
0.58
0.6
0.62
0.64
0.66
0.68
0.7
0.72
10-static-camo 100-static-camo 25-static-camo
50-static-camo 75-static-camo Naïve
Static Camouflage - Complexity Level
F1-Macro
(a)
Level 1.1 Level 1.2 Level 2.1 Level 2.2 Level 3.1 Level 3.2
0.6
0.62
0.64
0.66
0.68
0.7
10-dynamic-camo 100-dynamic-camo
25-dynamic-camo 50-dynamic-camo
75-dynamic-camo Naïve
Dynamic Camouflage - Complexity Level
F1-Macro
(b)
C-Te-10 C-Te-25 C-Te-50 C-Te-75 C-Te-100
0.55
0.6
0.65
0.7
0.75
10-static-camo 100-static-camo 25-static-camo
50-static-camo 75-static-camo Naïve
Static Camouflage - Instance camouflage ratio
F1-Macro
(c)
C-Te-10 C-Te-25 C-Te-50 C-Te-75 C-Te-100
0.55
0.6
0.65
0.7
0.75
10-dynamic-camo 100-dynamic-camo
25-dynamic-camo 50-dynamic-camo
75-dynamic-camo Naïve
Dynamic Camouflage - Instance camouflage ratio
F1-Macro
(d)
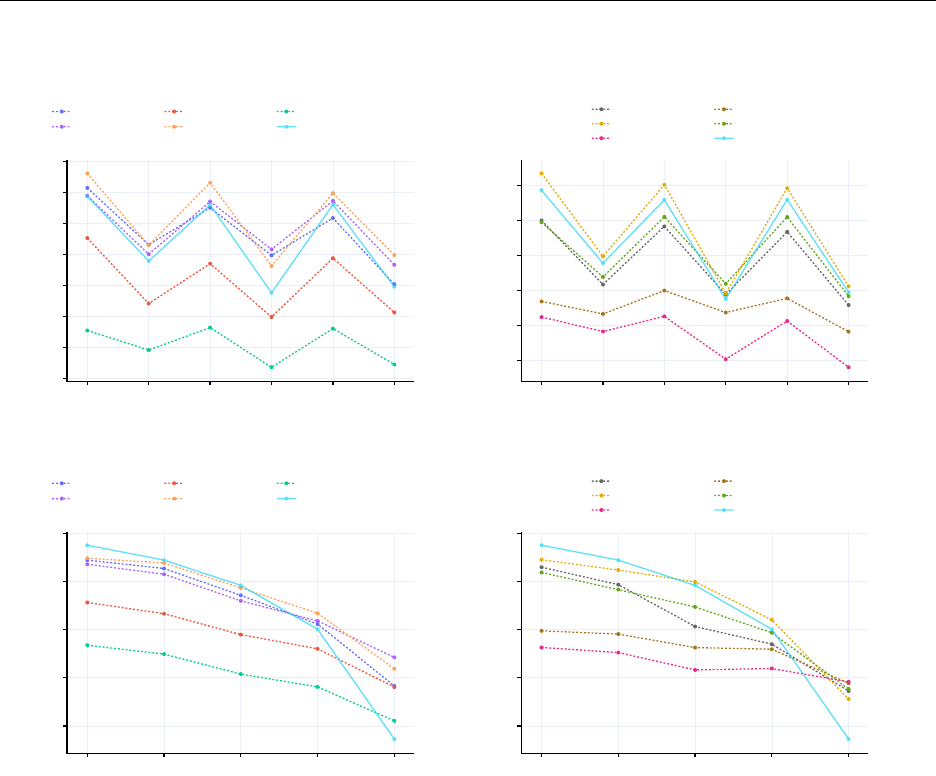
Figure 7: Comprehensive performance comparison of fine-tuned Encoder-Decoder models against naive models in
the Offensive Language task from OffensEval under various conditions. (a) Performance of Pre-camouflaged Models
across different levels. (b) Performance of Var-camouflaged Models across different levels. (c) Performance of Pre-
camouflaged Models across different camouflage percentages. (d) Performance of Var-camouflaged Models across
different camouflage percentages.
6 Conclusion
In response to the escalating prominence of adversarial attacks in Natural Language Processing (NLP), this research
presented a two-phase methodology to enhance Transformer models’ robustness. In the first phase, the susceptibility of
naive models to camouflage adversarial attacks was identified, demonstrating a clear need for improved defences.
A proactive strategy, incorporating adversarial training with both static and dynamic camouflage, was introduced in the
second phase. The models trained with a small proportion (10-25%) of statically camouflaged data outperformed those
trained entirely with static camouflage. Dynamic camouflage introduced during training further boosted the models’
learning and generalization capabilities.
In the comparison of various configurations, encoder-only models often excelled in managing adversarial attacks,
underscoring their superior adaptability. However, all configurations faced difficulties as the proportion of camouflaged
data increased, which emphasized the importance of balancing between original and camouflaged data in the training
set.
These findings carry significant implications for improving AI system robustness. Nevertheless, the limitations of this
study are acknowledged. The proposed approach’s effectiveness may fluctuate based on camouflage complexity and
15

Camouflage is all you need A PREPRINT
Encoder-Decoder - Constraint Results
Level 1.1 Level 1.2 Level 2.1 Level 2.2 Level 3.1 Level 3.2
0.7
0.75
0.8
0.85
0.9
0.95
10-static-camo 100-static-camo 25-static-camo
50-static-camo 75-static-camo Naïve
Static Camouflage - Complexity Level
F1-Macro
(a)
Level 1.1 Level 1.2 Level 2.1 Level 2.2 Level 3.1 Level 3.2
0.7
0.75
0.8
0.85
0.9
10-dynamic-camo 100-dynamic-camo
25-dynamic-camo 50-dynamic-camo
75-dynamic-camo Naïve
Dynamic Camouflage - Complexity Level
F1-Macro
(b)
C-Te-10 C-Te-25 C-Te-50 C-Te-75 C-Te-100
0.65
0.7
0.75
0.8
0.85
0.9
0.95
10-static-camo 100-static-camo 25-static-camo
50-static-camo 75-static-camo Naïve
Static Camouflage - Instance camouflage ratio
F1-Macro
(c)
C-Te-10 C-Te-25 C-Te-50 C-Te-75 C-Te-100
0.65
0.7
0.75
0.8
0.85
0.9
0.95
10-dynamic-camo 100-dynamic-camo
25-dynamic-camo 50-dynamic-camo
75-dynamic-camo Naïve
Dynamic Camouflage - Instance camouflage ratio
F1-Macro
(d)
Figure 8: Comprehensive performance comparison of fine-tuned Encoder-Decoder models against naive models in
the False Information Language task from Constraint under various conditions. (a) Performance of Pre-camouflaged
Models across different levels. (b) Performance of Var-camouflaged Models across different levels. (c) Performance of
Pre-camouflaged Models across different camouflage percentages. (d) Performance of Var-camouflaged Models across
different camouflage percentages.
the type of data encountered. Moreover, this research primarily concentrated on black-box adversarial attacks, leaving
other types largely unexplored.
Future research could expand this methodology to other adversarial attack types and model architectures, and further
explore the influence of camouflage complexity and type on model learning and robustness.
References
[1]
T. G. Dietterich, Steps toward robust artificial intelligence, AI Magazine 38 (3) (2017) 3–24.
doi:10.1609/
aimag.v38i3.2756.
[2]
S. Patil, V. Varadarajan, D. Walimbe, S. Gulechha, S. Shenoy, A. Raina, K. Kotecha, Improving the Robustness
of AI-Based Malware Detection Using Adversarial Machine Learning, Algorithms 14 (10) (2021) 297.
doi:
10.3390/a14100297.
[3]
W. E. Zhang, Q. Z. Sheng, A. Alhazmi, C. Li, Adversarial attacks on deep-learning models in natural language
processing: A survey, ACM Trans. Intell. Syst. Technol. 11 (3) (2020). doi:10.1145/3374217.
16

Camouflage is all you need A PREPRINT
[4]
E. Kotei, R. Thirunavukarasu, A systematic review of transformer-based pre-trained language models through
self-supervised learning, Information 14 (3) (2023). doi:10.3390/info14030187.
[5]
T. Wolf, L. Debut, V. Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz,
J. Davison, S. Shleifer, P. von Platen, C. Ma, Y. Jernite, J. Plu, C. Xu, T. Le Scao, S. Gugger, M. Drame, Q. Lhoest,
A. Rush, Transformers: State-of-the-art natural language processing, in: Proceedings of the 2020 Conference on
Empirical Methods in Natural Language Processing: System Demonstrations, Association for Computational
Linguistics, Online, 2020, pp. 38–45. doi:10.18653/v1/2020.emnlp-demos.6.
[6]
N. Papernot, P. McDaniel, I. Goodfellow, S. Jha, Z. B. Celik, A. Swami, Practical black-box attacks against
machine learning, in: Proceedings of the 2017 ACM on Asia Conference on Computer and Communications
Security, ASIA CCS ’17, Association for Computing Machinery, New York, NY, USA, 2017, p. 506–519.
doi:10.1145/3052973.3053009.
[7]
R. Jia, P. Liang, Adversarial examples for evaluating reading comprehension systems, in: Proceedings of the 2017
Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics,
Copenhagen, Denmark, 2017, pp. 2021–2031. doi:10.18653/v1/D17-1215.
[8]
W. H. Organization, et al., Infodemic management: an overview of infodemic management during covid-19,
january 2020–may 2021 (2021).
[9]
A. Martín, J. Huertas-Tato, Á. Huertas-García, G. Villar-Rodríguez, D. Camacho, FacTeR-Check: Semi-automated
fact-checking through semantic similarity and natural language inference, Knowledge-Based Systems 251 (2022)
109265. doi:10.1016/j.knosys.2022.109265.
[10]
G. Ruffo, A. Semeraro, A. Giachanou, P. Rosso, Studying fake news spreading, polarisation dynamics, and
manipulation by bots: A tale of networks and language, Computer Science Review 47 (2023) 100531.
doi:
https://doi.org/10.1016/j.cosrev.2022.100531.
[11] W. Xu, Y. Qi, D. Evans, Automatically evading classifiers: A case study on pdf malware classifiers, in: Network
and Distributed System Security Symposium, 2016.
[12]
J. Jeong, S. Kwon, M.-P. Hong, J. Kwak, T. Shon, Adversarial attack-based security vulnerability verification
using deep learning library for multimedia video surveillance, Multimedia Tools and Applications 79 (23-24)
(2020) 16077–16091. doi:10.1007/s11042-019-7262-8.
[13]
C.-L. Chang, J.-L. Hung, C.-W. Tien, C.-W. Tien, S.-Y. Kuo, Evaluating robustness of ai models against adversarial
attacks, in: Proceedings of the 1st ACM Workshop on Security and Privacy on Artificial Intelligence, SPAI ’20,
Association for Computing Machinery, New York, NY, USA, 2020, p. 47–54.
[14] M. Kavanagh, Bridge the generation gap by decoding leetspeak, Inside the Internet 12 (12) (2005) 11.
[15] A. Romero-Vicente, Word camouflage to evade content moderation (2021).
URL https://www.disinfo.eu/publications/word-camouflage-to-evade-content-moderation/
[16]
K. Blashki, S. Nichol, Game geek’s goss: linguistic creativity in young males within an online university forum,
2005. doi:10536/DRO/DU:30003258.
[17]
J. Fuchs, Gamespeak for n00bs - a linguistic and pragmatic analysis of gamers’ language, Ph.D. thesis, University
of Graz (2013).
URL https://unipub.uni-graz.at/obvugrhs/content/titleinfo/231890?lang=en
[18] R. Craenen, Leet speak cheat sheet.
URL https://www.gamehouse.com/blog/leet-speak-cheat-sheet/
[19] Z. Papakipos, J. Bitton, Augly: Data augmentations for robustness (2022). arXiv:2201.06494.
[20]
I. J. Goodfellow, J. Shlens, C. Szegedy, Explaining and harnessing adversarial examples (2015).
arXiv:1412.
6572.
[21]
M. Cheng, J. Yi, P.-Y. Chen, H. Zhang, C.-J. Hsieh, Seq2sick: Evaluating the robustness of sequence-to-sequence
models with adversarial examples (2020). arXiv:1803.01128.
[22]
P. Michel, X. Li, G. Neubig, J. Pino, On evaluation of adversarial perturbations for sequence-to-sequence models,
in: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational
Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Association for Computational
Linguistics, Minneapolis, Minnesota, 2019, pp. 3103–3114. doi:10.18653/v1/N19-1314.
[23]
M. Alzantot, Y. Sharma, A. Elgohary, B.-J. Ho, M. Srivastava, K.-W. Chang, Generating natural language
adversarial examples, in: Proceedings of the 2018 Conference on Empirical Methods in Natural Language
Processing, Association for Computational Linguistics, Brussels, Belgium, 2018, pp. 2890–2896.
doi:10.
18653/v1/D18-1316.
17

Camouflage is all you need A PREPRINT
[24]
N. Akhtar, A. Mian, Threat of adversarial attacks on deep learning in computer vision: A survey, Ieee Access 6
(2018) 14410–14430.
[25] B. Biggio, F. Roli, Wild patterns: Ten years after the rise of adversarial machine learning, in: Proceedings of the
2018 ACM SIGSAC Conference on Computer and Communications Security, 2018, pp. 2154–2156.
[26]
S. Singh, A. Mahmood, The nlp cookbook: Modern recipes for transformer based deep learning architectures,
IEEE Access 9 (2021) 68675–68702. doi:10.1109/ACCESS.2021.3077350.
[27]
D. E. Rumelhart, G. E. Hinton, R. J. Williams, Learning representations by back-propagating errors, nature
323 (6088) (1986) 533–536.
[28]
X. Zhang, J. Zhao, Y. LeCun, Character-level convolutional networks for text classification, in: C. Cortes,
N. Lawrence, D. Lee, M. Sugiyama, R. Garnett (Eds.), Advances in Neural Information Processing Systems,
Vol. 28, Curran Associates, Inc., 2015.
[29]
D. W. Otter, J. R. Medina, J. K. Kalita, A survey of the usages of deep learning for natural language processing,
IEEE transactions on neural networks and learning systems 32 (2) (2020) 604–624.
[30]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, Attention is all
you need (2017). arXiv:1706.03762.
[31]
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, P. J. Liu, Exploring the limits of
transfer learning with a unified text-to-text transformer (2020). arXiv:1910.10683.
[32]
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, BERT: Pre-training of deep bidirectional transformers for language
understanding, in: Proceedings of the 2019 Conference of the North American Chapter of the Association for
Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Association for
Computational Linguistics, Minneapolis, Minnesota, 2019, pp. 4171–4186. doi:10.18653/v1/N19-1423.
[33]
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, Language models are unsupervised multitask
learners, 2019.
[34]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry,
A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu,
C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish,
A. Radford, I. Sutskever, D. Amodei, Language models are few-shot learners (2020). arXiv:2005.14165.
[35]
B. Liang, H. Li, M. Su, P. Bian, X. Li, W. Shi, Deep text classification can be fooled, in: Proceedings of the
Twenty-Seventh International Joint Conference on Artificial Intelligence, International Joint Conferences on
Artificial Intelligence Organization, 2018. doi:10.24963/ijcai.2018/585.
[36]
M. Blohm, G. Jagfeld, E. Sood, X. Yu, N. T. Vu, Comparing attention-based convolutional and recurrent neural
networks: Success and limitations in machine reading comprehension, in: Proceedings of the 22nd Conference on
Computational Natural Language Learning, Association for Computational Linguistics, Brussels, Belgium, 2018,
pp. 108–118. doi:10.18653/v1/K18-1011.
[37]
C. Guo, A. Sablayrolles, H. Jégou, D. Kiela, Gradient-based adversarial attacks against text transformers,
in: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Association
for Computational Linguistics, Online and Punta Cana, Dominican Republic, 2021, pp. 5747–5757.
doi:
10.18653/v1/2021.emnlp-main.464.
[38]
R. Maheshwary, S. Maheshwary, V. Pudi, A context aware approach for generating natural language attacks
(2020). arXiv:2012.13339.
[39]
Y. Gil, Y. Chai, O. Gorodissky, J. Berant, White-to-black: Efficient distillation of black-box adversarial attacks
(2019). arXiv:1904.02405.
[40]
M. Li, J. Yu, S. Li, J. Ma, H. Liu, Textual adversarial attacks on named entity recognition in a hard label black box
setting, 2022 15th International Conference on Advanced Computer Theory and Engineering (ICACTE) (2022)
55–60.
[41]
Y. Deng, X. Zheng, T. Zhang, C. Chen, G. Lou, M. Kim, An analysis of adversarial attacks and defenses on
autonomous driving models (2020). arXiv:2002.02175.
[42]
K. Chiyomaru, K. Takemoto, Adversarial attacks on voter model dynamics in complex networks, Phys. Rev. E
106 (2022) 014301. doi:10.1103/PhysRevE.106.014301.
URL https://link.aps.org/doi/10.1103/PhysRevE.106.014301
[43]
M. F. Chen, M. Z. Rácz, An adversarial model of network disruption: Maximizing disagreement and polarization
in social networks, IEEE Transactions on Network Science and Engineering 9 (2022) 728–739.
18

Camouflage is all you need A PREPRINT
[44]
X. Yin, W. Lin, K. Sun, C. Wei, Y. Chen, A2s2-gnn: Rigging gnn-based social status by adversarial attacks in
signed social networks, IEEE Transactions on Information Forensics and Security 18 (2023) 206–220.
[45]
Álvaro Huertas-García, A. Martín, J. H. Tato, D. Camacho, Countering malicious content moderation evasion in
online social networks: Simulation and detection of word camouflage (2022). arXiv:2212.14727.
[46]
Y. Tang, C. Tran, X. Li, P.-J. Chen, N. Goyal, V. Chaudhary, J. Gu, A. Fan, Multilingual translation with extensible
multilingual pretraining and finetuning (2020). arXiv:2008.00401.
[47]
S. Biderman, H. Schoelkopf, Q. Anthony, H. Bradley, K. O’Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S.
Prashanth, E. Raff, A. Skowron, L. Sutawika, O. van der Wal, Pythia: A suite for analyzing large language models
across training and scaling (2023). arXiv:2304.01373.
[48]
L. Gao, S. Biderman, S. Black, L. Golding, T. Hoppe, C. Foster, J. Phang, H. He, A. Thite, N. Nabeshima, S. Presser,
C. Leahy, The pile: An 800gb dataset of diverse text for language modeling (2020). arXiv:2101.00027.
[49]
M. Zampieri, S. Malmasi, P. Nakov, S. Rosenthal, N. Farra, R. Kumar, SemEval-2019 task 6: Identifying and
categorizing offensive language in social media (OffensEval), in: Proceedings of the 13th International Workshop
on Semantic Evaluation, Association for Computational Linguistics, Minneapolis, Minnesota, USA, 2019, pp.
75–86. doi:10.18653/v1/S19-2010.
[50]
P. Patwa, S. Sharma, S. Pykl, V. Guptha, G. Kumari, M. S. Akhtar, A. Ekbal, A. Das, T. Chakraborty, Fighting
an infodemic: COVID-19 fake news dataset, in: Combating Online Hostile Posts in Regional Languages during
Emergency Situation, Springer International Publishing, 2021, pp. 21–29.
doi:10.1007/978-3-030-73696-
5_3.
19
