
ActionPrompt: Action-Guided 3D Human Pose
Estimation With Text and Pose Prompting
Hongwei Zheng
∗
, Han Li
∗
, Bowen Shi
∗
, Wenrui Dai
∗
, Botao Wang
†
, Yu Sun
†
, Min Guo
†
, Hongkai Xiong
∗
∗
Shanghai Jiao Tong University, Shanghai, China
Email: {1424977324, qingshi9974, sjtu shibowen, daiwenrui, xionghongkai}@sjtu.edu.cn
†
Qualcomm AI Research, Shanghai, China
Email: {botaow, sunyu, mguo}@qti.qualcomm.com
Abstract—Recent 2D-to-3D human pose estimation (HPE)
utilizes temporal consistency across sequences to alleviate the
depth ambiguity problem but ignore the action related prior
knowledge hidden in the pose sequence. In this paper, we propose
a plug-and-play module named Action Prompt Module (APM)
that effectively mines different kinds of action clues for 3D
HPE. The highlight is that, the mining scheme of APM can
be widely adapted to different frameworks and bring consistent
benefits. Specifically, we first present a novel Action-related
Text Prompt module (ATP) that directly embeds action labels
and transfers the rich language information in the label to the
pose sequence. Besides, we further introduce Action-specific Pose
Prompt module (APP) to mine the position-aware pose pattern
of each action, and exploit the correlation between the mined
patterns and input pose sequence for further pose refinement.
Experiments show that APM can improve the performance of
most video-based 2D-to-3D HPE frameworks by a large margin.
Index Terms—3D Human pose estimation, vision language
model, prompt learning
I. INTRODUCTION
3D human pose estimation (HPE) from a monocular image
or video has been widely considered in a variety of appli-
cations in human action recognition, robotics, and human-
computer interaction. 3D HPE usually follows a 2D-to-3D
pipeline that first estimates 2D joints from the input image
and then lifts the 2D joints to 3D pose. However, due to
the absence of depth information, this pipeline suffers from
the serious depth ambiguity problem [2]–[4] caused by the
many-to-one mapping from multiple 3D poses to one same
2D projection.
Recent attempts [5]–[9] exploit the temporal consistency
across sequences to alleviate these problems. However, they
only model the action-agnostic spatial and temporal correla-
tions but ignore the action related prior knowledge contained
in the pose sequence. As shown in Fig. 1(a), depth ambiguity
is more likely to occur in the part of feet for the action
SittingDown, whereas in the part of hands for the action Eat-
ing, since these parts usually have large motion. Furthermore,
Fig. 1(b) shows that 3D pose distributions significantly differ
for different actions in Human3.6M [10]. This fact suggests
that each action has unique characteristics that could benefit
Correspondence to Wenrui Dai.
Qualcomm AI Research is an initiative of Qualcomm Technologies, Inc.
Datasets were downloaded and evaluated by Shanghai Jiao Tong University
researchers.
SittingDown Eating
(a)
(b)
Fig. 1: (a) Examples in Human3.6M. (b) 3D pose distribution
of several actions in Human3.6M dataset by t-SNE [1].
pose estimation. It is necessary to effectively embed the action
clues into video-based 2D-to-3D pose estimation.
Existing methods form a multi-task learning framework to
embed the action clues by simultaneously considering pose
estimation and action recognition. In [11]–[13], the action
projector is introduced to classify the pose sequence with one-
hot action label but yields trivial performance gain in pose
estimation. We argue that this is because the action clues
cannot be fully mined by simply using the one-hot action
label in the classification sub-task. One-hot action label only
contains overall movement category information but ignores
the position and velocity information of the pose sequence.
Therefore, a more effective mining scheme for action label
needs to be carefully designed rather than such one-hot
manner.
In this paper, we propose a plug-and-play module named
arXiv:2307.09026v1 [cs.CV] 18 Jul 2023
Action Prompt Module (APM) that can mine different kinds of
action clues into HPE for better feature extraction. Motivated
by recent vision-language models (VLM) like CLIP [14],
which utilizes a huge amount of image-text pairs for pre-
training and can benefit the visual features with additional
information from text, we first propose a novel Action-related
Text Prompt module (ATP) that embeds each action label
into text prompts for the pose sequence feature enhancement.
Considering that CLIP pretrained model may lack knowledge
about pose sequence, we also design a Pose-to-text Prompt
(P2T) module in ATP to endow the text prompt embeddings
with velocity information. After obtaining the action-related
text prompts, we align the feature of pose sequence with
its corresponding prompt. In this way, the rich action-related
language information can be transferred to the pose sequence.
It’s worth noting that our ATP makes the first attempt to
leverage action-related language information from pre-trained
VLM model for HPE.
Though promising it is, text prompts of actions still lack
some position-aware information about human pose. Inspired
by our finding that some representative poses for the same ac-
tion are shared across different subjects, as shown in Fig 1(a),
we further propose an Action-specific Pose Prompt module
(APP) to effectively mine and exploit these action-specific
pose patterns, which are position-aware and shared across
different subjects. In particular, for each action, we utilize
some pose prompts as a learnable action-specific pattern to
capture typical position-aware information. Then we perform
cross attention by regarding feature of pose sequence as query,
and these pose prompts as key and value, thus matching the
learnable action-specific representative position-aware infor-
mation with input pose sequence and refine pose feature to
obtain more accurate 3D estimated pose.
The proposed APM is a general plug-and-play module to
improve existing video-based 2D-to-3D pose estimation mod-
els. We seamlessly employ our method to three recent state-
of-the-art models, including VPose [5], A3DHP [6] which
are the classic model using temporal convolutions [15] and
MixSTE [7] which is the current SOTA model based on
Transformer [16]. The proposed APM is shown to improve
all the models on the Human3.6M and HumanEva-I datasets.
Remarkably, it achieves an average gain of more than 5% in
MPJPE for all the models. Furthermore, the proposed APM
alleviates the depth ambiguity of different actions, especially
for hard actions.
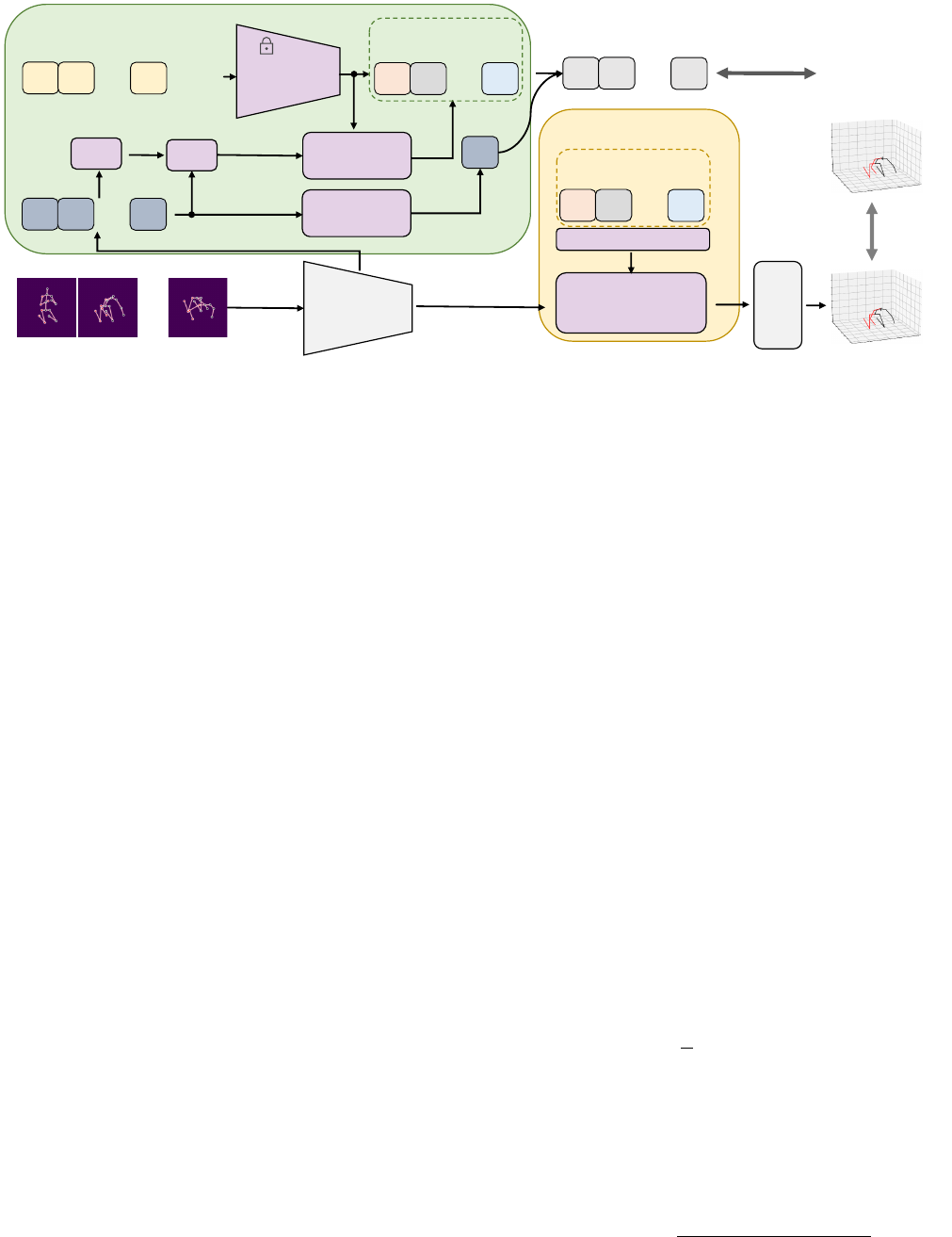
II. ACTION PROMPT MODULE
Fig. 2 illustrates the proposed plug-and-play Action Prompt
Module for video-based 2D-to-3D HPE models. APM con-
sists of two sub-modules, i.e., Action-related Text Prompt
(ATP) and Action-specific Pose Prompt (APP). Taken 2D
pose sequence as the input of pose encoder, ATP directly
embeds action labels and transfers the action-related language
information to the pose sequence by aligning poses with
texts in the feature space. APP mines the position-aware pose
pattern of each action and exploits the correlation between the
patterns and pose feature for further refinement. The refined
pose feature is leveraged to predict the target 3D pose.
A. Action-related Text Prompt
ATP exploits the rich action-related language information
to align the pose features with text features. Given the input
2D pose sequence X ∈ R
F ×J×2
that contains F frames
and J joints for each frame, we obtain the C-dimensional
pose features of the shallow layer Z
0
∈ R
F ×C
in the pose
encoder and then project them into the action features A ∈ R
C
by Action Projector. Meanwhile, the learnable text prompts
V ∈ R
K×N×C
, where K denotes the number of action classes
and N denotes the number of text prompts, are encoded by
the text encoder to obtain K-action text prompt embeddings
T ∈ R
K×C
containing action-related information. In addition,
Pose-to-Text Prompt endows the text prompt embedding T
with velocity information contained in the pose features Z
0
.
Finally, we can get the classification vector y ∈ R
K
calculated
between the enhanced text prompt embedding
¯
T and action
feature A for feature alignment. As highlighted in green in
Fig. 2, ATP includes the text prompt design for 3D HPE,
Action Projector, and Pose-to-Text Prompt.
Design of Text Prompt. We firstly introduce text prompt
design to embed action label in a learnable manner. Inspired by
CoOp [17], we utilize learnable text prompts as our templates
by optimizing them in the training process. In order to adapt
to 3D HPE, we fill up the [CLS] token with various action
class names in text prompts. The input of the text encoder can
be formulated as:
V = [V ]
1
[V ]
2
...[V ]
N
[Action]
k
, k = 1, ..., K, (1)
where [V ]
i
∈ R
C
is the randomly initialized learnable template
and is shared by all action classes and [Action]
k
∈ R
C
represents the corresponding action class. The text prompts V
are input to the text encoder, whose parameter is frozen except
for the final text projection layer during training. Then, we can
obtain the K-action text prompt embeddings T , containing
rich action-related language information.
Action Projector. We propose the Action Projector to extract
the action-related information contained in the pose features.
As pose features propagate through the VPose encoder, the
time dimension of pose features reduces from F to 1, which
means that the temporal information is lost as the network
deepens. Therefore, we connect the Action Projector with the
the shallowest layer of the pose encoder that contains more
general information for action recognition, and get action
features A, i.e., A = Proj(Z
0
). The Action Projector is
realized using D
2
TCN [15] blocks.
Pose-to-Text Prompt. Inspired by DenseCLIP [18], we pro-
pose the Pose-to-Text Prompt module, which endows the
text prompt embeddings with velocity information via cross
attention layer, thus making up the lack of knowledge about
pose sequence in pretrained CLIP model. In that case, the
enhanced text prompts can describe the action more accurately
and concretely. For example, the text prompt “a video of
walking fast” is more accurate than “a video of walking”, as it
[Photo]
[Eating]
[…]
[]
1
[]
2
[]
n
…
[
]
1
[
]
2
[
]
k
…
[]
Re
[P]
1
[P]
2
[P]
k
…
Pose Encoder
Pose Prompt
Pose-to-Text
Prompt
Linear
Projection
Concat
Action label
K-action pose
prompt embeddings
K-action text prompt
embeddings
Action-related Text Prompt
(ATP)
Action-specific Pose
Prompt (APP)
[
]
1
[
]
2
[
]
f
…
Action Select
[]
1
[]
2
[]
k
…
Diff.
Text Encoder
Action
Projector
…
[]
1
[]
2
[]
f
Fig. 2: The overview of Action Prompt Module (APM), which is a plug-and-play module consisting of two sub-modules,
i.e., Action-related Text Prompt (ATP) and Action-specific Pose Prompt (APP). Taken 2D pose sequence as the input of pose
encoder, ATP directly embeds action labels and transfers the rich action-related language information to the pose sequence by
aligning poses with texts in the feature space. Then, APP mines the position-aware pose pattern of each action and exploits
the correlation between the patterns and pose feature for further refinement. Finally, we predict the target 3D pose with refined
pose feature. The architecture of pose encoder and linear projection is according to baseline model. (The text encoder is frozen
during training and is abandoned during inference.)
incorporates the velocity information of pose movement. Thus,
we extract the first-order motion information of pose features
Z
0′
∈ R
(F −1)×C
, which is the difference of neighbor frames
of Z
0
, to represent the velocity and concatenate the pose fea-
tures Z
0
and Z
0′
to obtain
¯
Z
0
, i.e.,
¯
Z
0
= Concat(Z
0
, Z
0′
).
Subsequently, the text prompt embedding T is fed into the
cross-attention as queries while
¯
Z
0
as keys and values to
obtain the output
ˆ
T . In that way, the text features can find the
most related pose clues. The enhanced text prompt embedding
¯
T is achieved by combining
ˆ
T and T .
B. Action-specific Pose Prompt
We develop the Action-specific Post Prompt (APP) to
address the problem that text prompts with action label still
lack position-aware information about human pose. APP mines
the position-aware pose pattern of each action, and exploits
the correlation between the mined patterns and input pose
sequence for pose refinement.
In APP, we propose the learnable pose prompts P ∈
R
K×L×C
as learnable action-specific patterns, where L is
the number of pose prompts for each action. It is worth
noting that there are K-class pose prompt templates which are
action-specific because they are designed to learn more fine-
grained information compared with the text prompts. During
training, the pose prompts
ˆ
P ∈ R
L×C
are selected according
to the given action label. Then we perform cross attention
by regarding the output pose features of the pose encoder
Z
d
∈ R
1×C
as query, and select pose prompts
ˆ
P as key and
value in the Transformer decoder [16].
ˆ
Z
d
= TransDecoder(Z
d
,
ˆ
P ). (2)
In this case, the pose features are matched with the most
related pose pattern of the corresponding action. Similarly, we
refine the pose features through the residual connection:
¯
Z
d
= Z
d
+ γ
ˆ
Z
d
, (3)
where γ ∈ R
C
is the learnable parameter to scale the residual
ˆ
Z
d
. Finally, the target 3D pose Y ∈ R
J×3
is obtained from
the refined pose feature
¯
Z
d
through linear projection.
Note that the text encoder of ATP is only needed in
the training process, which facilitates model deployment in
the real world. During inference, the optimized text prompt
embeddings of all the actions are saved locally to infer action
label, thus APP can select the pose prompts of corresponding
action to refine pose features.
C. Training Loss
The overall training loss L = L
P
+λ·L
A
balances the pose
loss L
P
and action loss L
A
with a trade-off factor λ.
Pose Loss. The pose loss L
P
is formulated as
L
P
=
1
J
J
X
i=1
∥
ˆ
Y
i
− Y
i
∥
2
, (4)
where
ˆ
Y
i
and Y
i
are respectively the ground truth and esti-
mated 3D joint location of the i-th joint.
Action Loss. The classification vector y ∈ R
C
is predicted
using the cosine similarity between the text prompt embedding
¯
T and the action feature A.
p(y = i|x) =
exp(cos(
¯
T
i
, A)/τ)
P
K
j=1
exp(cos(
¯
T
j
, A)/τ)
, (5)

TABLE I: Quantitative evaluation results of Action Prompt Module attached to various pose encoders on Human3.6M (with an
input length F of 243). The inputs for the top group are ground truth (GT) of 2D pose while the bottum group are the detection
2D pose from HRNet [19](denoted by
∗
). The per-action results are shown in P1 and avgerage P1, P2, P3 are calculated.
Method Walk WalkT. Eat Pur. WalkD. Phone Smoke Greet Dir. Wait Photo Disc. Pose SitD. Sit P1 P2 P3
VPose 29.3 30.0 34.8 37.8 37.0 35.5 36.9 36.3 36.9 37.7 40.2 41.1 41.4 45.9 45.8 37.8 33.6 39.3
+APM 26.6 27.1 34.0 35.8 36.1 35.1 34.8 36.0 34.9 33.9 39.1 37.2 39.2 43.4 42.0 35.7(-2.1) 29.7(-3.9) 33.8(-5.5)
A3DHP 26.2 26.8 33.5 34.5 35.7 37.4 35.5 35.3 34.3 39.1 44.9 39.1 39.7 49.5 46.4 37.2 33.4 41.2
+APM 24.8 26.4 31.4 31.7 35.1 36.4 35.0 33.6 31.5 36.4 44.5 37.1 37.4 49.5 43.8 35.6(-1.6) 31.9(-1.5) 38.8(-2.4)
MixSTE 15.7 16.1 22.4 23.3 23.2 23.1 23.5 23.1 23.6 24.1 28.5 24.3 26.5 32.0 30.2 24.0 21.8 27.5
+APM 15.9 16.7 21.1 22.5 22.1 21.8 22.7 21.9 22.3 23.0 25.8 21.8 25.1 30.2 27.9 22.7(-1.3) 19.9(-1.9) 24.7(-2.8)
VPose
∗
37.0 38.8 43.4 42.6 49.1 49.3 45.9 47.4 44.5 45.2 53.4 47.0 46.3 67.6 55.6 47.5 34.6 41.7
+APM
∗
36.7 38.7 43.5 41.7 49.3 48.7 45.0 47.2 42.2 43.8 52.1 45.2 44.3 65.3 53.5 46.5(-1.0) 33.3(-1.3) 39.8(-1.9)
A3DHP
∗
36.1 38.3 43.5 41.9 47.9 50.0 45.7 47.2 43.4 46.1 56.9 45.6 45.6 71.0 56.9 47.7 35.3 43.7
+APM
∗
35.8 38.2 43.5 41.1 47.4 49.9 45.7 46.2 42.8 45.7 56.1 44.7 43.7 68.5 54.5 46.9(-0.8) 34.2(-1.1) 42.0(-1.7)
MixSTE
∗
31.8 32.8 40.6 38.3 42.6 43.8 42.0 40.9 37.6 40.5 49.1 40.3 39.4 65.2 52.9 42.5 30.9 38.9
+APM
∗
30.5 31.6 39.8 38.9 42.0 43.1 42.0 40.6 37.7 40.0 48.0 40.2 38.8 63.2 50.8 41.8(-0.7) 29.5(-1.4) 36.8(-2.1)
where τ is a temperature parameter. We then define the action
loss L
A
as the cross-entropy loss between the ground truth ˆy
and predicted classification vector y.
L
A
= CrossEntropy(ˆy, y). (6)
III. EXPERIMENTS
A. Experimental Settings
Datasets. Human3.6M [10] is the most commonly used
indoor dataset for 3D HPE that contains 3.6 million images
of 11 subjects and 15 actions. Following [5]–[7], we take five
subjects (S1, S5, S6, S7, S8) for training and another two
subjects (S9, S11) for testing. We evaluate our method and
conduct ablation studies on the Human3.6M. HumanEva-I [20]
is further adopted to demonstrate the generalization ability of
the proposed method. It consists of seven calibrated sequences
for four subjects performing six actions. Following [6], [7], we
test our models on the actions of Walk and Jog.
Evaluation Metrics. Follow previous work [5]–[7], we use the
mean per-joint position error (MPJPE) as evaluation metric.
To evaluate the effect on the alleviation of depth ambiguity,
we also provide the position error of depth axis, termed as
D-MPJPE. In addition, we calculate the D-MPJPE of three
hardest actions (Posing, SittingDown and Sitting), termed as
Tail D-MPJPE, to focus on these actions with significant error.
In the following parts, We abbreviate MPJPE, D-MPJPE, Tail
D-MPJPE as P1, P2 and P3, respectively.
Implementation Details. The proposed method is imple-
mented with PyTorch. The text encoder in APP loads weight
from the pretrained text encoder in CLIP [14]. To demon-
strate the effect of the proposed method, we apply APM
to several existing video-based 2D-to-3D HPE methods, in-
cluding VPose, A3DHP, and MixSTE. λ is set to 0.1. For
fair comparison, we apply the same parameter settings as
the corresponding baseline experiments in [5]–[7]. We set the
number of blocks of MixSTE to 4 to reduce the consumption
of GPU memory.
B. Experimental Results
Table I shows the performance results of different actions.
Following previous work [5]–[7], in the top group, we take
TABLE II: Quantitative evaluation results on HumanEva-I
over Walk and Jog by subject.
Method Walk Jog P1 P2
VPose 20.5 15.9 30.5 36.1 23.0 25.7 25.3 19.0
+APM 18.8 16.2 30.3 33.1 21.8 24.7 24.1(-1.2) 16.6(-2.4)
A3DHP 17.5 13.1 26.4 19.5 17.9 21.5 19.3 12.8
+APM 16.1 12.2 25.4 19.2 16.6 20.2 18.3(-1.0) 11.5(-1.3)
MixSTE 18.7 18.0 26.4 27.8 18.0 20.0 21.5 18.1
+APM 17.4 17.3 25.2 26.6 17.2 18.2 20.3(-1.2) 16.4(-1.7)
the ground truth (GT) 2D pose as input to predict the 3D
pose. In the bottom group, we use the HRNet [19] as 2D
pose detector to obtain 2D joints for benchmark evaluation.
The improvements on the various baseline models, 2D pose
types and protocols demonstrate the superior effectiveness and
generality of our action-aware design. In addition, the Tail D-
MPJPE presents greater improvement than D-MPJPE for all
baseline models, which means that our model can brings more
benefits for poses of hard actions. The results on HumanEva-I
are shown in Table II, which further verify the generalization
ability of our method.
Furthermore, Fig. 3(b) intuitively shows the improvement
of D-MPJPE in different methods. The results demonstrate
that our method can significantly reduce the prediction error
on depth axis, especially for hard actions with higher depth
ambiguity. Fig. 4 shows the qualitative results on some hard
actions in Human3.6M. Compared with baseline, our method
can alleviate the depth ambiguity caused by self-occlusion.
C. Ablation Studies
Ablation studies are performed to further validate the design
of each component, where APP is not added in the ablation
studies on ATP. We take the 2D ground truth on Human3.6M
as the input sequence (with an input length F of 243) and
VPose as the baseline.
Each component in APM. We first evaluate the effect of
each component of our Action Prompt Module, as shown in
Table III. Firstly, we introduce the action recognition task
as the sub-task using a projector the same as the Action
Projector, termed as “Action Label”. There is only 0.2mm

(a)
(b)
Fig. 3: (a) D-MPJPE distribution of different actions on three
baseline models. (b) Analysis of APM on hard actions. Our
proposed Action Prompt Module mainly benefit hard actions
with higher predicting errors.
and 1.5mm gain under two protocols, which means that multi-
task learning strategy benefits 3D HPE slightly. By adding
ATP, VPose achieves 4.2% and 10.1% improvement under two
protocols respectively, proving that the action-related language
knowledge is effectively facilitated for the feature extraction
of pose sequence. In addition, by adding APP and replacing
ATP with the simple action projector to infer the action label,
VPose obtains 3.2% MPJPE improvement and 6.5% D-MPJPE
improvement, which means that the mined position-aware pose
pattern of each action can refine the estimated pose. Finally,
by combing ATP with APP, VPose achieves the best result
boosted 5.6%.
Each component in ATP. Since the ATP module does not
depend on APP, we verified the effect of each component of
ATP by removing APP for convenience. Firstly, we adopt the
simplest design for Action Projector by using global average
pooling, which can benefit 3D HPE a lot already. However,
we argue that amounts of temporal information is lost in this
way. We introduce TCN blocks to project the pose features,
which further brings 0.5mm improvement in MPJPE. Finally,
further adding Pose-to-Text Prompt to refine the text prompt
embeddings achieves the best result.
K-action text prompt. As shown in Table V, we remove
the text encoder, and directly set the K-action text prompt
embeddings T as learnable parameters. Compared with di-
rectly using action label for multi-task learning, learnable K-
action embeddings bring a better performance, while our ATP
can boost more. The results show that extra action-related
information counts for 3D HPE. And with text encoder, we
can endow more abundant information in the language domain
into the pose sequence.
TABLE III: Ablation study on each component of Action
Prompt Module. Acc denotes the accuracy of the predicted
action labels.
Action Label ATP APP P1 P2 Acc.
Baseline 37.8 33.6 -
✓ 37.6 32.1 90.2%
✓ ✓ 36.2 30.2 94.6%
✓ ✓ 36.6 31.4 91.5%
Ours ✓ ✓ ✓ 35.7 29.7 96.2%
TABLE IV: Ablation study on each component of ATP. GP
denotes global average pooling.
Action Projector
P2T P1 P2
GP TCN
Baseline 37.8 33.6
✓ 36.9 31.7
✓ 36.4 30.9
✓ ✓ 36.7 31.3
Ours w/o APP ✓ ✓ 36.2 30.2
TABLE V: Ablation study on K-action text prompt. APP is
added into the model.
Method P1 P2
Multi-task 36.6 31.4
K-action text prompt 36.3 30.9
ATP (ours) 35.7 29.7
Fig. 4: Qualitative results on Human3.6M.
Length of input sequence. As shown in Table VI, we explore
the effect of input sequence length. The result shows that as
the input sequence length increases, the benefit from ATP
gets greater. ATP achieves 2.4mm improvement in MPJPE
when inputting 243 frames. It shows that long length input
sequence contains long-range temporal information, which can
precisely reflect the characteristics of action. In contrast, when
the input length is small, the short-time frames are just a
small part of the action, which contain ambiguous action-
related information. Therefore, it makes sense that ATP is
more suitable for long input sequence.
Position of Action Projector. Table VII shows the effect of the
position of Action Projector. We connect the Action Projector
with different layers of VPose. We find that as the connected
layer deepens, the model performance gets worse. From the
1st layer to the 5th layer, MPJPE increases 13.3%. When the
connected layer is 4 and 5, the extracted action information
misleads the pose estimation. It can be inferred that the shallow
layer features contain more general information while the

TABLE VI: Ablation study on input sequence length.
Frames P1 P2 P3
9 39.8 35.2 43.2
9+ATP 40.2(+0.4) 34.9(-0.3) 42.2(-1.0)
27 39.1 34.9 41.2
27+ATP 38.3(-0.8) 32.9(-2.0) 38.0(-3.2)
81 38.1 33.8 40.4
81+ATP 37.0(-1.1) 31.5(-2.3) 35.5(-4.9)
243 37.8 33.6 39.3
243+ATP 36.2(-1.6) 30.2(-3.4) 34.1(-5.2)
TABLE VII: Ablation study on the position of Action Projec-
tor.
Layer P1 P2 P3
5 41.0(+3.2) 33.9(+0.3) 40.8(+1.5)
4 38.6(+0.8) 32.5(-1.1) 39.0(-0.3)
3 37.3(-0.5) 31.2(-2.4) 37.5(-1.8)
2 36.8(-1.0) 30.7(-2.9) 37.0(-2.3)
1 36.2(-1.6) 30.2(-3.4) 34.1(-5.2)
TABLE VIII: Ablation study on APP with GT action label.
Method P1 P2
APP w. GT 36.4 31.0
APP w/o. GT 36.6 31.4
TABLE IX: Ablation study on different parameters of APP. C
is the embedding dimension. D and L denote the number of
APP layers and pose prompts, respectively.
D C L P1 P2 Params(M)
1 256 81 35.7 29.7 22.87
4 256 81 35.8 29.3 24.45
1 128 81 36.0 29.4 22.33
1 1024 81 35.8 29.5 31.61
1 256 27 36.2 29.9 22.76
1 256 243 36.3 30.1 23.21
deeper reflect more specific information related with target
3D pose, which deviates from the action recognition task.
APP with GT action label and action prediction accuracy.
Since the action label inferred by our ATP could produce a
certain error rate, as shown in Table VIII, using the GT action
label to select the pose prompt for adjustment can yield a slight
performance gain. We also list the accuracy of the action labels
prediction for different variants of our method in Table III. We
can infer that MPJPE is positively correlated with the accuracy,
and our method can also boost the accuracy compared with
simply introducing the action recognition task as the sub-task.
Parameters in APP. Table IX evaluates the impact of pa-
rameters in APP on the performance and complexity of our
model. We find that using one transformer block obtains the
best result and stacking more blocks does not yield gains. The
result shows that enlarging the embedding dimension from
128 to 256 can boost the model performance, but cannot bring
further benefits when using dimension 1024. In addition, we
find that 81 pose prompts can yield the best result.
IV. CONCLUSION
In this paper, we proposed a plug-and-play module, named
Action Prompt Module (APM), to mine action clues for 3D
HPE. We first present a novel Action-related Text Prompt
module (ATP) that adapts the rich action-related language
information in action label to the pose sequence. Secondly,
to mine the position-aware pose pattern of each action, we
introduce Action-specific Pose Prompt (APP), which refines
pose feature by exploiting the correlation between learnable
patterns with input pose sequence. APM can be applicable to
the most video-based 2D-to-3D HPE methods, and extensive
results on Human3.6M and HumanEva-I reveal the benefits of
our design for 3D pose encoders.
V. ACKNOWLEDGEMENT
This work was supported in part by the National Nat-
ural Science Foundation of China under Grants 61932022,
61931023, 61971285, 61831018, and 61972256.
REFERENCES
[1] L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.” JMLR,
vol. 9, no. 11, 2008.
[2] A. Zeng, X. Sun, L. Yang, N. Zhao, M. Liu, and Q. Xu, “Learning
skeletal graph neural networks for hard 3d pose estimation,” in ICCV,
2021, pp. 11 436–11 445.
[3] H. Li, B. Shi, W. Dai, Y. Chen, B. Wang, Y. Sun, M. Guo, C. Li,
J. Zou, and H. Xiong, “Hierarchical graph networks for 3d human pose
estimation,” in BMVC, 2021.
[4] H. Li, B. Shi, W. Dai, H. Zheng, B. Wang, Y. Sun, M. Guo, C. Li,
J. Zou, and H. Xiong, “Pose-oriented transformer with uncertainty-
guided refinement for 2d-to-3d human pose estimation,” AAAI, 2023.
[5] D. Pavllo, C. Feichtenhofer, D. Grangier, and M. Auli, “3d human pose
estimation in video with temporal convolutions and semi-supervised
training,” in CVPR, 2019, pp. 7753–7762.
[6] R. Liu, J. Shen, H. Wang, C. Chen, S.-c. Cheung, and V. Asari,
“Attention mechanism exploits temporal contexts: Real-time 3d human
pose reconstruction,” in CVPR, 2020, pp. 5064–5073.
[7] J. Zhang, Z. Tu, J. Yang, Y. Chen, and J. Yuan, “Mixste: Seq2seq mixed
spatio-temporal encoder for 3d human pose estimation in video,” in
CVPR, 2022, pp. 13 232–13 242.
[8] C. Zheng, S. Zhu, M. Mendieta, T. Yang, C. Chen, and Z. Ding,
“3d human pose estimation with spatial and temporal transformers,” in
CVPR, 2021, pp. 11 656–11 665.
[9] A. Zeng, L. Yang, X. Ju, J. Li, J. Wang, and Q. Xu, “Smoothnet: a
plug-and-play network for refining human poses in videos,” in ECCV.
Springer, 2022, pp. 625–642.
[10] C. Ionescu, D. Papava, V. Olaru, and C. Sminchisescu, “Human3. 6m:
Large scale datasets and predictive methods for 3d human sensing in
natural environments,” TPAMI, vol. 36, no. 7, pp. 1325–1339, 2013.
[11] D. C. Luvizon, D. Picard, and H. Tabia, “2d/3d pose estimation and
action recognition using multitask deep learning,” in CVPR, 2018, pp.
5137–5146.
[12] D. C. Luvizon, D. Picard, and H. Tabia, “Multi-task deep learning for
real-time 3d human pose estimation and action recognition,” TPAMI,
vol. 43, no. 8, pp. 2752–2764, 2020.
[13] K. Liu, Z. Zou, and W. Tang, “Learning global pose features in graph
convolutional networks for 3d human pose estimation,” in ACCV, 2020.
[14] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal,
G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable
visual models from natural language supervision,” in ICML. PMLR,
2021, pp. 8748–8763.
[15] C. Lea, M. D. Flynn, R. Vidal, A. Reiter, and G. D. Hager, “Temporal
convolutional networks for action segmentation and detection,” in CVPR,
2017, pp. 156–165.
[16] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez,
Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” NIPS, vol. 30,
2017.
[17] K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Learning to prompt for vision-
language models,” IJCV, vol. 130, no. 9, pp. 2337–2348, 2022.
[18] Y. Rao, W. Zhao, G. Chen, Y. Tang, Z. Zhu, G. Huang, J. Zhou, and
J. Lu, “Denseclip: Language-guided dense prediction with context-aware
prompting,” in CVPR, 2022, pp. 18 082–18 091.
[19] K. Sun, B. Xiao, D. Liu, and J. Wang, “Deep high-resolution represen-
tation learning for human pose estimation,” in CVPR, 2019, pp. 5693–
5703.
[20] L. Sigal, A. O. Balan, and M. J. Black, “Humaneva: Synchronized video
and motion capture dataset and baseline algorithm for evaluation of
articulated human motion,” IJCV, vol. 87, no. 1, pp. 4–27, 2010.
